4. 亲自体验你的产品
新系统的设计者不仅应当是实现者和第一位大规模用户;设计者还应写出第一版用户手册……如果当时我没有完整参与这些活动,字面意义上几百处改进都不会发生,因为我根本想不到它们,也意识不到它们为何重要。
— Donald Knuth
假设你正准备发布产品的新版本,希望先让用户试用。可你的产品规模还不够大,也还没有一群随叫随到、愿意在短时间内体验预发布版本的忠实 beta 用户。多数用户在尝试你的新版本前,还有别的优先事项。即便确实有人试用,也未必会触达设计中风险最高的部分。截止日期近在眼前,于是你很容易动念:在没有用户验证的情况下直接发布。
但其实,确实有一批更容易调动的“用户”可用:你自己、你的队友,以及公司里的同事。这些人和你共享产品成功带来的收益,天然就有动力帮你。
Tip
让自己成为第一位客户。这样能更早、更便宜、几乎无害地验证产品。
当团队成员使用自己做的产品时,这就叫内部试用(dogfooding)。这个词在 20 世纪 90 年代的微软被广泛传播,当时微软形成了使用其操作系统和编译器最新版本的文化。它来自短语“eating your own dogfood(吃自己的狗粮)”,用来表达团队为了测试自家产品愿意做到什么程度。
当你或同事本身就在目标人物画像之内,并且能模拟真实世界使用条件时,内部试用尤其理想。但即使条件不完美,只要团队足够了解用户,并能“换鞋思考(shoe-shifting)”去扮演真实用户,内部试用仍然会非常有效。
想办法去做。如果你是农业科技公司,可以买一块自己的农田来测试产品;如果这不现实,也可以在温室、实验室或计算机里模拟这些条件;或者你也可以聘请真正的农民,让他们拿出一部分土地供你实验。
内部试用有几个关键优势:
内部试用的形式比你想象得更多。本章会覆盖四种方法:
- 编写场景测试来演练产品,模拟真实世界使用。
- 通过编写使用指南,把“使用你的产品到底是什么体验”铺展开来。只要足够细致,它能提前预警问题。
- 自己写或让队友写“摩擦日志(friction logs)”,详细记录内部试用体验。这既能促进大家持续试用,也能产出更有价值的反馈。
- 为合适的产品创建示例(samples)并测试它们。
文档与自动化测试在传统上不被视为内部试用,但如果做得好,它们都包含大量“扮演用户”的过程,并会对产品施加有价值的压力。
请有创造性地组合这些手段,以低成本在每一步都验证你的产品。这样你能降低风险,并确保不会浪费用户的时间与信任。
将测试用于内部试用
当你进入写代码阶段后,写测试是“亲自体验你的产品”的最佳方式之一。Kent Beck 说过:“测试驱动开发(TDD)旨在消除应用开发中的恐惧。”要降低这种恐惧,最好的办法就是编写与生产环境高保真的测试。
在 TDD 中,测试写在实现之前。但依据是什么?它们不可能从实现推导出来,因为实现还不存在!如果实现已经存在,就会引入实现偏见(implementation bias),变成在断言“代码现在做了什么”,而不是“它本该做什么”。
因此,主要且可靠的灵感来源是用户场景。不要先写代码,再按你已经写出的行为去补测试;应当在被实现细节“带偏”之前先写测试。这样更容易贴近用户场景。
本节我想展示如何把测试当作内部试用机会。通过精心挑选的自动化测试,我们可以做到:
- 验证关键场景下的正确性。
- 打磨边界情况。
- 记录预期用法。
- 逼自己想清楚到底在构建什么。
- 构建可长期复用、可反复执行的资产。
但在此之前,我们先快速盘点各种测试类型,重点看哪些最值得投入。
你应该写哪些测试?
为便于统一语境,我先定义几类测试。它们融合了“系统导向”与“产品导向”。系统导向测试用于降低系统风险,即应用有 bug、不可靠或不可扩展的概率;产品导向测试用于降低产品风险,即用户无法完成任务的概率。
你的目标应是:让测试集高效发现系统与产品两类问题,因此必须搭配多种测试。以我经验看,很多软件团队对产品导向测试投入不足,而工程师也未必意识到可用测试类型的广度。
- Mocks:非功能性的占位替身,用来验证依赖是否按特定方式被调用。
- Fakes:复杂功能的简化替代实现。例如,SQLite 是基于本地文件系统的 SQL 实现,可以作为真实 SQL 数据库的 fake。
下面这份清单按它们对代码库施加“产品压力(product pressure)”的强弱排序。
Note
所谓产品压力,是指根据用户个人与群体最可能采取的动作序列而进行的验证。
- 单元测试(Unit tests):测试小块代码,如单个函数或类。通常在功能开发早期编写,用来探查边界情况并编码契约。它们应运行很快,服务于最内层开发循环。为聚焦测试目标,常会使用 mocks。但它们并不特别擅长发现重要的系统和产品问题。
- 集成测试(Integration tests):测试多个组件,承认“组件交互”往往最脆弱。它们会减少 mock 依赖,更好地嗅探系统问题;多数情况下运行真实生产代码,必要时调用 fakes。相较单元测试,它更可能发现产品问题,但仍不如下面几类测试那样强调产品场景。
- 功能测试(Functional tests):聚焦单个功能的产品行为。可用 fakes 模拟依赖,如其他服务与数据库。若没有 fake,有些测试会用 mocks,但这是种“坏味道(bad smell)”,会让测试更难被信任。
- 场景测试(Scenario tests):类似功能测试,但它验证的是常见用户场景而非具体功能。它通常会覆盖多个功能,或用最常见输入集合来验证某个功能,确保完整用户任务可完成。
- 负载模拟(Load simulations):用大量合成请求给产品加压。理想情况下,这些请求应模拟真实世界条件,我会在第 9 章详细讨论。
- 端到端测试(End-to-end, e2e):面向用户行为最全面的自动化测试,也能发现意料之外的系统集成问题。本质上它是“什么都不桩替”的场景测试,通常包含用户界面。
- 用户验收测试(User acceptance testing):让真实用户手动试跑你的产品并反馈问题。稍后介绍摩擦日志时我会进一步讨论。
图 4-1粗略展示了各类测试的相对优劣。
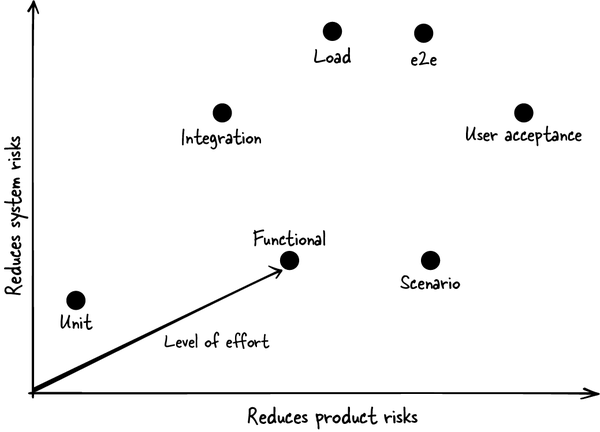
图 4-1. 按可发现的系统风险与用户风险绘制的测试类型
选择测试类型
- 最小化最关键、足以导致产品不可用的系统与产品风险
- 确保在发现(Discovery)阶段得到的关键场景已被测试覆盖
- 通过自动化减少重复的人肉验收测试
- 在编写成本给定的前提下,提升测试价值
- 让测试具备高信噪比,失败时大概率值得关注
- 通过功能测试覆盖关键边界情况
系统风险高的功能应包含负载模拟、集成测试等;产品风险高的功能应更多投入功能测试、场景测试和用户验收测试。端到端测试两类风险都适用。要想清楚:你产品里最“新”的部分是什么,也就是最可能出故障的部分。比如你在替换全新基础设施组件,语义却沿用多年不变,那么你可能更该关注系统测试,并更多依赖既有测试覆盖产品行为。反过来,如果你在成熟科技公司里用稳健基础设施和最佳实践(“paved roads”)构建新产品,就可以更偏重产品风险。两类风险都重要,大多数测试都应包含两者要素。但因为这是一本讲产品思维的书,本章重点放在场景测试、功能测试、e2e 测试和用户验收测试。负载模拟我会在第 9 章再谈。
只测用户在乎的东西
前面我们谈到要覆盖系统与产品风险。但时间预算有限时,如何优先级排序最关键的测试,以及这些测试里最关键的断言?
总目标应该是:测试断言必须直接对应用户在乎的行为。
- 过度依赖实现细节与 mocked 依赖的单元测试,常随代码演进而频繁维护。我甚至会在功能测试补齐后,删掉一些实现阶段写的单元测试。
- 过度挑剔、断言过细的 e2e 测试,会随着产品表面变化而频繁失效。
- 提供不真实流量模式的负载模拟,会把你引向永远用不到的扩容和加固方向。
为了演示如何选测,我用流媒体服务 Netflix 举例。用户通过浏览器访问 Netflix。假设我们在 Web 团队,主要职责是让首页展示可观看内容。页面是可点击播放的节目网格。每一行有不同主题,如“Critically Acclaimed TV Shows”和“My List”;继续下滚会出现更多行,如“Classic Science Fiction and Fantasy”,或算法认为用户会感兴趣的内容。
场景测试
场景测试捕捉真实世界的产品使用方式。由于它直接映射“用户会做什么”,因此非常容易抓住关键 bug。实际上,我们可以把发现(Discovery)阶段整理出的场景直接翻译成场景测试,具体过程见第 7 章。
场景测试促使我们跳出单一功能,从用户视角思考产品。它无法独自覆盖完整测试矩阵,但如果选得好,能确保即便带着 bug 发布,也多为相对轻微的问题。
这类测试通常会组合至少两个常一起出现的元素。例如:
- 在同一用户流程里组合两个或更多经常共同出现的功能。组件交互往往是软件最不稳定的部分,场景测试正好覆盖它。
- 用最常见数据类型、按贴近真实世界的规模来运行功能。
场景测试应尽可能端到端,其余部分使用高保真 fake。若我们在后端团队,不跑浏览器往往更方便或更经济,可以改用模拟 DOM 环境。(DOM 是网页结构与内容对象的数据表示。)另外,测试里直接使用 Netflix 的真实分布式数据库成本会高得离谱。图 4-2展示了一个 Netflix 后端场景测试系统图,左右两侧都用了 fake。

图 4-2. 典型后端场景测试配置
下面是基于该配置的后端场景测试示例:一个已登录用户想看电影,访问 netflix.com,点击某个电影缩略图,加载电影并开始播放。
伪代码如下:
# A logged in user wants to watch a movie, so they load the home page
def watch_movie_from_homepage():
set_up_fake_movies() # Don't want to download and play movies in our tests.
# User sees the home page. It should have thumbnails of movies.
home_page_source = get_source("netflix.com")
home_page_dom = get_dom(home_page_source)
movie_listing = find_one("movie_thumbnail", home_page_dom)
assert(movie_listing)
# User clicks one of the movies.
watch_movie_page_request = movie_listing.click_target()
watch_movie_source = get_source(watch_movie_page_request)
watch_movie_dom = get_dom(watch_movie_source)
# Movie page loads successfully and starts playing automatically
assert_autoplay_on(watch_movie_source)注意这个测试如何把每一步动作串接到下一步。我们并没有硬编码 watch_movie_page_request,而是从 HTML 和 JavaScript 里提取。它无法发现所有 UI 层问题(比如控件在屏幕上被遮住),但能确保首页返回的电影页链接是正确的。
测试还通过注释与命名讲述了用户场景故事。可自解释的场景测试尤其重要,因为它本质上是“被固化下来的产品需求”。当新成员加入团队时,场景测试应该是你最先给他看的内容之一。
再给几个测试思路:
- 下滚触发第二页:渲染首页后,模拟用户下滚,系统加载更多节目行。断言初始页渲染时包含可拉取更多数据的 URL;触发该 URL 对应动作,确认新内容被加载。
- 新用户体验:创建全新的 Netflix 测试账号。因为系统尚不了解该用户,首页应展示最热门内容。节目数据库预填一些合成数据,并指定其中一组最热门,确认热门节目出现。
- 用户想续播正在观看的节目:渲染节目库,确认页面某处出现“从上次进度继续播放”的元素。
功能测试
并非所有内容都要写成场景测试。功能测试用于在更大测试矩阵内,针对单个功能进行更细致的多用例验证,尤其是边界情况。
继续 Netflix 例子,我们可以写这些功能测试:
- 渲染主题行,如“My List”“Critically Acclaimed TV Shows”
- 边界情况,如用户列表为空时渲染“My List”
- 点击电影条目中的不同元素(播放、点赞、更多信息),并确认渲染出对应页面
端到端测试
端到端测试与场景测试类似,但对系统与产品行为覆盖更全面。应把它配置在最关键的核心场景上。
继续 Netflix 的例子,这类测试可使用“无头浏览器(headless browser)”来模拟真实点击,而不只验证底层功能。它也可能运行在预发布或 QA 环境的数据库上,而非 fake 数据库,如图 4-3所示。

图 4-3. 典型 e2e 测试配置
由于它跑在真实线上节目数据上,测试必须对内容变化具备韧性。以“新用户体验”场景为例,作为 e2e 测试时,我们不该硬编码“最热门电影”,而应在测试中额外查询当前最热门节目。如果是 Squid Game 最新一季,就应期望它出现在首页。
这类测试能在很多位置发现场景测试可能漏掉的问题:也许填充热门电影数据库的夜间任务没跑;也许新用户建号流程即将回归;也许某个 UI 元素被无意间隐藏了。
它还可能发现延迟回归。单次运行速度波动可能太大,难做稳定断言,但你可以对每条 e2e 流程做多次运行并看平均速度,判断是否退化。
团队通常不会写太多 e2e 测试,但它占据关键位置。即便运行频率低于其他测试,只要它能阻挡关键发布就有价值。
如果你的断言和假设不贴近用户价值,端到端测试会严厉惩罚你。你硬编码的短 sleep 在繁忙测试环境里会超时,应改为回调或轮询等待。你测试页面上的“第三个元素”会因设计师重排而改变,应给 UI 元素加持久语义标签,以便自动化检索。例如在 Netflix 页面上,我们应能通过 play_video 或 more_info 标签定位按钮。
用户验收测试
在用户验收测试中,你会让部分员工或志愿者在预发布环境里跑给定场景,并要求这些测试通过后才能发布。常见场景包括:
- 国际化与本地化:不同语言、不同地区的使用者在多种条件下验证产品行为,这些组合复杂到工程师难以自行全面覆盖。
- 合规标准要求的人工测试。
- 对大型语言模型(LLM)输出进行人工验证。尤其是红队测试(red teaming),即用户以对抗思维尝试诱导 AI 执行其未被设计去执行的行为。
依赖真人测试会慢、也贵,但既然你在追求验证,就应在自动化尚未准备好或不可行时,愿意并能够搭建这类流程。
更多时候,我看到人们以其他方式挖掘用户反馈,我会在第 5 章展开。
总体而言,自动化测试是“双重利器(dual threat)”:前期它能提供关键内部试用价值;后期它能长期保留,并在产品演进中持续产出价值。
文档也是同样意义上的双重利器。
文档驱动开发
你听过“教是最好的学”这句话吗?对“教别人使用产品”这件事同样成立:写文档是在教别人,也是在学习你的产品并发现改进点的绝佳方式。
工程师经常要为技术产品编写或评审文档,我非常建议深度参与这件事。若你不擅长写作,可以和同事以及/或 AI 助手协作:你提供技术内容与一线洞察,发挥你在构建产品、理解用户过程里积累的编辑判断。
但从内部试用角度看,在产品周期更早阶段先勾勒文档,能避免后期代价高昂的错误。
你会更早发现问题并改进产品。上一节讲的是测试驱动开发(TDD);这一节要讲的是我认为几乎同样有用的方法:文档驱动开发(Documentation-Driven Development)。文档草稿常常比测试更早、更便宜就能写出,甚至在代码尚未诞生前。
在讲“把文档用于内部试用”之前,我先给一些通用建议:如何组织文档,以便在正确时机回答正确问题。
本节将覆盖四个主题:
- 文档能力边界的注意事项
- 面向不同用户场景构建不同文档:发现、理解、使用
- 帮助用户找到文档,并在不同场景间顺畅切换
- 将写文档本身作为内部试用练习
文档不应成为承重结构
用户通常并不想读你的文档。用户花在找文档和读文档上的时间,本可直接用于完成任务。即便会查看内容,他们也往往是选择性阅读,而非从头读到尾。
结合第 2 章,当你想依赖文档来强化产品发现地图时要谨慎。别忘了用户知识有三层:已知、已知未知、未知未知。
“已知未知”通常是这类特性与行为:用户基于使用相似产品的经验,知道自己应该期待什么,即便他们还没在你的产品里亲自遇到。这里列出一些常见“未知未知”:
- 出乎意料的危险行为
- 新功能
- 让你区别于竞争对手的非标准功能
应使用意符(signifier,见第 2 章),如通知和弹窗,提示用户新功能与差异化的非标准功能。为了防止有害行为,应限制可供性(affordance,见第 8 章),并提供确认机制(见第 3 章)。
有了这个前提后,我们仍要承认:对更复杂的产品,文档既不可避免,也确实有用。即便用户不直接阅读,AI 助手也会读取你写下的一切,并转述给用户。
文档读者的场景
我合作过的许多软件工程师(包括过去的我)要么不写文档,要么一写就是参考文档。我们很自然会按功能逐项解释“我们做了什么”。
但让我们换鞋思考:你到底多久才会用一次参考指南?在这些场合里,你又有多少次是在尝试其他文档类型无果后,才退回参考指南?下面我拆开讲。
在第 2 章中,我介绍过用户旅程:用户会经历发现、理解、使用三个阶段。这三类活动都可能需要文档支持。
- 发现(Discovery):用户(常常是新用户)知道自己的目标,但不知道该用哪个产品或哪个功能来实现。
- 理解(Understanding):用户在某处卡住,需要加深对产品的理解,学习可复用概念以提高效率。即便还不是,他们也很可能正走向高黏性用户。
- 使用(Usage):用户知道该用哪个产品或功能,但不知道如何正确使用。可能是新用户,也可能是正在挑战高级功能的老用户。
下面这个例子顺便也让我对自己早年学 C++ 的痛苦释怀一点。
我大学第一门编程课学的是 C++。教材是 Bjarne Stroustrup 的 The C++ Programming Language。在第 3 版中,这本书是对语言的全景式总览。可那时我只是勉强自保:想找到做算法作业的合适工具、学会基础概念。结果我得到的是作者一章接一章炫示 C++ 各种高深又偏门特性的“高级用法文档”。
这也许是本好书。若我是有多年 C++ 经验的资深工程师,或许收获更大;但它在当时对我并不合用。我真希望教授选一本更符合人物画像的教材。本书一位审稿人也提到:他曾因“目标不准的学习材料”退出计算机专业,后来又重返该领域,成为资深首席工程师和专业计算机教师。像 C++ 这样复杂的产品,迫切需要循序渐进的引导。
当时我需要的是入门指南,而那本书却是参考指南。也就是说,在我需要“发现与理解”支持时,它却把重点放在“使用”场景。
这些场景各自需要不同文档类型,如表 4-1所示,并且这种差异从用户旅程起点就存在。
表 4-1. 文档类别
| 文档类型 | 场景 |
|---|---|
| 人物画像菜单(Persona menu) | 发现 |
| 场景菜单(Scenario menu) | 发现 |
| 入门指南(Getting started guide) | 理解 |
| 概念指南(Conceptual guide) | 理解 |
| 使用指南(Usage guide) | 使用 |
| 运维指南(Operational guide) | 使用 |
| 参考指南(Reference guide) | 使用 |
这一段我用 Docker 作为例子。Docker 是一个流行的平台,用于开发、交付和运行应用。它最著名的抽象是“容器(container)”:一种把依赖打包在一起的可执行程序,可在多种计算环境中分发与运行。
发现
首先,他们想知道自己是否属于目标人物画像。你的产品或功能“是不是给我用的”?这能给他们一个预期:当他们继续深入细节时,你的设计选择是否适配他们。
对全新用户而言,最常见且有效的方法之一,是在应用或网站上提供人物画像菜单(persona menu)。例如今天我访问打车网站 lyft.com,会看到“Rider”“Driver”“Business”等入口。它明确告诉我:如果我属于这些画像之一,我就在其服务对象之列,并可点击了解详情。
Tip
明确你要服务的人物画像,并为每类画像定制文档。
当人物画像匹配成立后,潜在用户接着会看产品是否覆盖他们的场景。
Docker 当前网站没有人物画像菜单,但它有场景菜单(scenario menu)。它列了三个场景:
- 快速且一致地交付应用
- 响应迅速的部署与扩缩容
- 在同一硬件上运行更多工作负载
用户据此会更清楚 Docker 是否能解决自己的问题。
注意这些标题里都没有“container”这个词,尽管它是 Docker 最知名概念。这是因为不熟悉容器的用户通常不会搜“container”,但会搜上面这些场景描述里的词。
Tip
在用户所在之处与其相遇;区分“用户带着什么认知而来”与“用户接下来必须学会什么”。
除了顶层产品发现外,用户在实际使用中不断发掘功能,还会发生大量“小发现”。你需要像第 2 章里画的产品发现地图那样,引导他们在不同文档之间跳转,或从产品界面跳到文档。
理解
入门指南(Getting started guides)把用户推进到“可以开始探索并使用产品”的状态。也就是说,它帮助用户从发现阶段过渡到理解与使用阶段,同时通过“边做边学”进行教学。
我在第 1 章提到过,用户希望尽量少分配脑力给“学习你的产品”。与记忆概念相比,按入门指南一步步操作更容易。
但对复杂产品而言,你可能还需要概念指南(conceptual guide),用于讲解产品本体(ontology)——这个词在第 2 章中被定义为“结构化的产品词汇体系”。
Tip
用概念指南讲清那些会在产品中反复复用的原语或概念。
当用户需要后退一步、真正把东西学明白时,概念指南就很关键。有一次我想把一个程序打包进 Docker 容器,反复受阻,Docker 的使用指南也帮不上忙。我意识到自己需要先更好理解 Docker,虽然当时说不清到底缺了哪块知识。于是我去读了讲 Docker 核心原语的概念指南。我学到一个对我场景极有价值的点:Docker 容器可以彼此嵌套(nest)。问题瞬间变简单了。
和大多数读者一样,我当时也是个“被迫学习者”,总希望只靠使用指南混过去,尽快把任务做完走人。
和所有文档一样,你需要讲得出“用户会怎样发现概念指南”这条故事线。应在其他文档类型里大量链接到它。也许 Docker 若能在使用指南里直接指向“容器嵌套”这个概念,我会省下大量时间,不必完整读完一整篇指南。
一个关键发现技巧是:为核心概念提供同义词,以优化搜索命中,避免用户带着另一套本体进来却搜不到内容。
使用
当文档读者开始执行具体任务时,他们就成了真正的用户。对 Docker 来说,我理解了容器嵌套后,下一步就需要知道如何创建它们。
使用类文档常见有三种:使用指南、运维指南、参考指南,分别满足略有差异的需求。
使用指南(usage guides),或操作指南(how-to guides),与入门指南很像,都是给出逐步流程来完成任务;不同之处在于,它不只是“介绍产品”,而是帮助用户达成一个具体目标。若你的产品需要文档,应为最关键场景(如各项目的北极星场景)都写使用指南。即便产品不需要对外文档,你也可以先勾勒这些指南,用作有目的的内部试用。
用户会如何找到这些文档?取决于他们所处场景:
- 如果他们知道要做什么,但不知道该用什么功能,文档应按任务命名,或至少可按该任务关键词搜索到。Docker 网站有“Configure CI/CD”“Deploy to Kubernetes”等指南。
- 如果他们已经知道需要哪个功能,就会按功能名查找。Docker 里有“Building Compose objects”“Containerize your app”等直接写出功能名的指南。
- 他们也可能从产品本身发现目标文档,例如由错误消息跳转,或从其他相关任务/概念文档跳转而来。
确保你从多个角度提供指向使用指南的“可发现入口”。Docker 有个有趣的文档标签系统,用户可点击如“DevOps”“Deployment”等标签找到匹配指南。
*运维指南(operator’s guides)*是使用指南的一种特殊类型,常被称为故障排查指南(troubleshooting guides)或 runbooks。阅读这类文档的用户通常是第一次遇到该故障模式,处在陌生地带。
因为它们用于“出事时刻”,就必须能从错误消息里被发现,这在第 3 章讨论过。应让它们支持深链(例如 docs.docker.com/dhi/troubleshoot/#no-shell, …/#no-package-manager)到具体问题,方便支持人员、错误消息和自动化机器人响应直接链接到精确修复方案。同时务必保持这些链接稳定且最新。
最后一种使用文档是参考指南(reference guide)。它通常面向单个功能,在细节深度上覆盖更全面。
就像场景测试不会像功能测试那样穷尽每个功能细节一样,使用指南也不会覆盖所有细节。使用指南可以外链到参考指南,由后者按功能或概念逐项展开,讨论细节、边角条件和高级用法。
事实上,这些文档类型和测试类型是对应的:
- 场景测试或 e2e 测试,可能覆盖与使用指南或运维指南条目相同的地带。
- 某个功能的一组功能测试,通常会覆盖该功能参考指南提到的全部行为。
回头对照你的场景测试,看看是否缺少对应使用指南,反之亦然,这个检查很值得做。
文档之网
学习应发生在它被需要、且学习者有兴趣的时候。
— Don Norman,The Design of Everyday Things 作者
用户不会总是沿着“发现→理解→使用”直线前进。相反,他们在工作过程中会在这些场景间顺滑切换。选定产品后,发现会变成理解;使用中若冒出新问题,使用又会变回发现。问题一出现,用户立刻被抛进运维指南;一旦不知道下一步怎么做,他们就会从使用切回理解。
因此,文档之间以及产品到文档之间都应高度互链。构建“面包屑路径(trails of breadcrumbs)”,帮助用户从使用或排障场景升级到学习模式,并从眼前问题走向解决方案。使用指南提到关键概念时应链接到概念指南;概念指南应链接到示例说明。以此类推。
Tip
构建一张相互链接的文档网络。
将写文档作为内部试用
设想你在写一个开源开发者工具,并正在编写“如何安装软件包”的入门指南。
为了换鞋思考,你搭了一个全新环境,从零在机器上安装,让你的环境尽可能贴近新用户。
结果你不断遇到错误,开始意识到过去几周开发过程中你在本机悄悄设置了多少工具和环境变量。回头看指南,它已经变得很长!
你不满意,于是决定发布一个把依赖全部打包进去的容器,让用户不用逐项安装。随后你删除了指南里那堆烦人的步骤,换成更短的容器运行说明。
再设想你是某 SaaS 服务值班工程师,刚刚支持了几位内存耗尽、艰难排障的用户。你在写 runbook 条目告诉他们该怎么做时,突然意识到:如果一开始允许用户自行设置某些资源限制,这个问题本可完全避免。你先发布 runbook 条目,但随后立即着手通过新增配置从根本上消除对它的需求。
写文档的过程会强迫我们换鞋思考,去走用户旅程。写着写着若感觉又繁琐又难解释,我们就会不耐烦。
如果你写得足够用心,就能把这份“痛感”转化为产品改进动力。关键窍门是:在仍然便宜可改的时候尽早做。下面是把文档写作融入开发流程的几个例子:
- 在开始设计前先写人物画像菜单和场景菜单。亚马逊著名做法是在项目开头先写“模拟新闻稿”,预测产品上线后如何对外沟通。它像正式新闻稿一样向用户解释价值主张。采用这种“营销先行”实践,有助于你理解目标画像并评估产品价值。
- 在功能早期版本可用时尽早写使用指南。记录不必要步骤和棘手决策,在“修起来还便宜”时捕捉可用性问题。
- 写概念指南,帮助团队就关键抽象的精确描述达成一致。若写起来非常挣扎,考虑重命名或重构表述;若某概念看起来并非用户真正关心,也许你需要提供更高层抽象。
- 强迫自己向用户解释“你这个功能允许发生的问题该如何排查”。很多时候,修复安全性问题的成本,甚至低于你去写文档、做沟通并持续支持踩坑客户的成本。
另一个高效用法是:先想象理想的产品体验。在尚未写任何代码前,就把未来用户体验写出来并分享给队友。随后你的项目应实现所有必要功能,让文档描述变成真实。
这种文档驱动开发可以非常早、非常深地融入你的开发流程。
总体来说,对某些产品,文档既服务人类也服务 AI,在发现、理解、使用场景都提供帮助。即便产品不对外发布文档,写“模拟文档”也会让你聚焦同样的场景,并让内部试用更有参与感。
测试和文档都很重要,但我们也需要外部视角。外部用户时间有限,因此我们需要一个轻量方法让他们帮忙。答案就是摩擦日志。
摩擦日志
我们已经写了场景测试、写了指南,也常在使用产品早期版本时校对其准确性。但即便最优秀的产品思考者,也会经常被“其他人类到底会怎么用”惊到。是时候引入用户了,不过先从更宽容的一群开始。
在内部试用中,我们用的是公司自己构建的软件,而写*摩擦日志(friction logging)*是非常好的做法。
摩擦日志是在你使用产品时写下的非正式文档,记录你经历的困惑和阻碍。完成后交给负责该产品的工程师或 PM。
摩擦日志会把你的内部试用精力导向“有价值”的使用。知道最后要提交一份短文档,也会激励你坚持体验下去。
在接下来的两个小节,我会先讲如何写摩擦日志,再讲如何让其他人也为你的产品记录摩擦。
我在 Stripe 工作时学到摩擦日志,它是那里的文化之一。尤其是当时的 CTO David Singleton,每年会花几周时间体验产品与内部基础设施的不同角落,并写摩擦日志。
有一周他内部试用了我在做的内部 Workflow Engine,那对我和团队都非常振奋。他甚至“卧底”了一把:通过其他工程师在我们的支持频道提问,以便在大家不知道提问者是 CTO 的情况下观察支持体验,避免偏见。他的摩擦日志积极且建设性很强。
David 改进了产品、鼓舞了我们,也帮助工程团队维持了友善、建设性的摩擦日志文化,同时让他自己持续掌握产品与基础设施现状。
写摩擦日志
摩擦日志是以“摩擦”为重点的场景日志。你的目标很简单:报告你对产品的真实体验,产品团队会按他们的判断去使用这些信息。
下面是一份关于在社交应用 Instagram 上编辑并发布视频的摩擦日志示例:
摩擦日志示例
我是 Drewbie(Drew + Newbie),Instagram 新用户,但之前用过 TikTok。我想上传一个视频,但要把声音关掉。
我在 iPhone 上开始发帖。因为我还没给 Instagram 授权“整个照片与视频库”,我先进入“管理隐私”,挑了一个视频授予权限;然后又选了一次这个视频把它用于发帖。我知道一些新应用已经把这个流程做得更顺滑了,所以会疑惑 Instagram 为什么没有。
我看到一排图标,其中有个麦克风。我点了麦克风,希望它能静音视频,结果弹出了一个带播放按钮和“tap to add audio”按钮的“scrubber(拖动条)”。这和我预期不一致。
我没看到明显有帮助的图标,但在摸索时无意向右滑,才发现屏幕外还有更多图标可选。然后我看到一个“loudspeaker(扬声器)”图标,可以静音。这部分就非常直接;我还注意到一个很酷的“voice boost”功能,我觉得以后会用上。
注意我是在描述体验,而不是给规定式建议。Instagram 团队很可能比我更清楚什么可行、什么更合适。比如他们若想处理“扬声器图标难发现”问题,可以把图标排成两行,或让一个图标半露出屏幕边缘,暗示“这里可横向滚动”。
我作为摩擦日志记录者的职责,只是把问题指出来。如果我直接说“你们应该把图标改成两行”,他们可能会觉得我在替他们做工作、替他们定路线图;也可能仅否定这个具体方案,从而错过对其他方案的发散。你越不了解被反馈的团队,就越要谨慎拿捏边界。
我略过了一些体验顺畅的流程,但在合适处也点缀了赞赏。这能让摩擦点更突出,也让产品团队知道哪些方向是对的。
写完后,把它交给团队,并预期他们会筛选反馈、分诊行动项。
接收摩擦日志
接收摩擦日志非常有用。知道用户如何真实体验你的产品,这就是黄金信息。
但你怎么让别人愿意来体验你的产品?摩擦日志虽有趣,但大家都很忙,没有回报通常不会做。可考虑这些人群:
- 你自己:戴上新手帽。
- 早期采用者:请他们写摩擦日志。
- 新同事:邀请他们把记录摩擦当作熟悉产品细节的上手方式。
- 开发者、设计师、数据科学家等:组织社交化产品体验活动,如 bug bash 或 hackathon。
拿到反馈时,不要有防御心态,把它当礼物:
- 如前所述,不要让反馈者去提工单或走流程。这会设置门槛,让人更不愿投入时间,也会传递“你的反馈不值得我花时间”的信号。
- 闭环反馈。如果某人的摩擦日志推动了改进,要告诉他,最好还能让其经理也看见。我们公司有一套“kudos”机制专门做这件事。
- 如果你或团队已经压力过载,不要迁怒信使。把时间压力留在后续分诊阶段处理。
摩擦日志文化
摩擦日志应是一个安全空间:你可以自由点评、挑剔别人的产品;接收方也能安心决定“是否”以及“何时”优先处理。只要双方角色清晰,互动通常都很棒。
如果它能成为文化惯例,会更容易。没有明确规范时,突然给某团队提反馈会显得带攻击性或批评意味,也不清楚你是否期待他们立刻停下手头工作来修你的问题。你在挑小毛病时,也可能担心别人觉得你吹毛求疵。预期不清会放大彼此冒犯焦虑。
如果它还不是惯例,你可以利用“这是一种互联网上已有定义的实践”这一点。此前我在当前公司引入它时,引用了现有博客来解释我在做什么,反馈很好。很快我就看到其他人也开始写摩擦日志。
摩擦日志是一种有趣且高效的内部试用方式,你应把它纳入产品流程并主动征集。
本章结尾我想讲“示例(samples)”:它们是展示产品常见应用方式的参考例子。示例如果做好,能把测试、文档与摩擦日志优雅地结合起来。
示例
并非所有产品都适合用示例,但对效率工具、创意工具和产品开发类应用,示例通常收益很大。举例来说,假设你的产品是类似 Microsoft Excel 或 Google Sheets 的电子表格程序。
和测试、文档一样,示例也有多种类型:
- 功能示例:类似功能测试,聚焦演示单一功能,如排序或筛选。
- 场景示例:类似场景测试与使用指南,演示一组协同功能以支撑关键用户场景。比如“办公用品预算表”既体现通用预算最佳实践,又能直接帮助正在做办公预算的人。
以下就用后者,展开几条编写示例的建议:
- 给示例加自动化测试,既保障其可用,也可兼作场景或 e2e 测试。比如确保预算模板加载无报错;测试可填入一些数字并检查剩余现金。
- 要具体,使用具体场景和具体语言。可预填一个叫“iniTECH”的软件公司,采购项写成“红色订书机”“蟑螂药”这类可信条目。用户从具体例子外推,比从“item 1”“foo”这类抽象词里消歧容易得多。
- 像代码注释那样告诉用户“为何这么设计示例”。若预算示例面向表格新手,你可以加简短说明标题,并链接到“相对/绝对单元格引用”的文档。
- 思考发现场景:用户遇到问题时,如何找到正确示例?对于功能示例,如果用户不知道该功能能解问题怎么办?你可以把模板列在模板目录;模板多时可加标签系统,并归入“accounting”或“finance”。
- 在编写示例时同步写摩擦日志,把你的体验反馈回产品。如果示例由其他团队负责编写,也应欢迎他们报告摩擦。
本章小结
在产品设计与开发全程中,要主动寻找方式去亲自使用你的产品,并对其施加产品压力,确保它经得起真实世界使用。
测试并非生而平等:有些更适合测产品,有些更适合测系统。场景测试与端到端测试能可靠地记录产品行为并确保持续可用,功能测试则补齐覆盖面的空白。
同样,文档也不是只有一种用途。用户旅程的不同场景需要不同类型文档。使用指南与入门指南是结构化体验产品的好方式,而早期编写概念指南能帮助你和团队打磨想法与产品沟通策略。
最后,摩擦日志是从同事那里获取可执行且坦诚的体验反馈的优秀方式。
练习
- 选一个你感兴趣的 Wikipedia 页面,再选其中一行文字。找出这行文字的原始作者,并用摩擦日志记录你的体验。
- 阅读我对第一题所写的摩擦日志。假设你是 Wikipedia 开发团队新人,任务是处理这份反馈并打磨 UI。你会补充收集哪些信息?会优先探索哪些改进?
- 你在 WikiBlame 功能团队,正在补强测试覆盖。(可通过任意感兴趣的 Wikipedia 页面进入 WikiBlame:点击“View History”,再选“Find addition/removal”。)请给出一份至少包含两个关键场景测试的测试计划。假设你的测试框架支持模拟 UI 交互。
- Microsoft PowerPoint 有个“Animation”功能,允许演讲者通过一系列点击逐步展示幻灯片内容。其使用指南里有一节叫“Animate or make words appear one line at a time”。从文档三大用户场景角度看,他们为什么这样命名?
最后留个作业:把你正在做的某样东西写成文档。若还没实现,就按你想象中的形态,为一个关键用户场景写文档;若它已经存在,就亲自走一遍推荐流程,再按你的体验写出对应文档。
参考答案
- 这是我在尝试给 Wikipedia 一行文字溯源作者时写的摩擦日志。请确保你的版本也记录了人物画像与使用意图,并以体验报告为主,不要过于直接地给出具体改进方案。
我是 Drewbie,一名软件工程师。过去我主要把 Wikipedia 当读者工具,自己名下编辑很少,所以对高级用户工具并不熟。在阅读“历届 Microsoft Puzzle Hunts”页面时,我发现其中一条链接损坏,但不确定正确链接是什么,于是想联系最初编辑者。
作为工程师,我习惯用 git blame 给源码行溯源作者,所以我希望这里也有类似功能。我先点了“View history”,但这个界面对我不可用,而且没有“blame”按钮。我又猜“View source”也许行,于是找了“blame”及相似入口,依然无果。
我回到修订历史更仔细地看。“Find edits by user”行不通,因为我不知道用户名。到这一步我去查了 Google,结果告诉我去点“Find addition/removal”。
在那个名为 WikiBlame 的页面上(噢,“blame”),我找到一个术语搜索框,于是选了我关心那行文本里的一段短语去搜索。结果里出现如下条目:
Comparing differences in 02:48, 31 August 2005 between 210 and 211 while coming from 196:OOComparing differences in 04:34, 11 August 2005 between 217 and 218 while coming from 210:XX我看不太懂这些内容,尤其是那些数字以及 XX、OO。但在列表底部我看到:Insertion found between 02:37, 31 August 2005 and 02:41, 31 August 2005: hereInsertion 看起来像这行文字的起点,于是我点了 here。可我到处都找不到用户名!找了一分钟后,我发现了一个 IP 地址,这才明白是匿名用户通过该 IP 提交了编辑。(如果有明确标签会更清楚。) 如果我把这份日志交给 Wikipedia 团队,他们会自行筛选。对“没有 blame 按钮”的反馈,他们可能会忽略,因为这个词更符合工程师画像,不一定是多数编辑者的常用术语。另一方面,我对“IP 地址其实代表用户名”这点的困惑是普适的,可能会促使他们加上类似 Author 的标签。 - 如果我是应用团队成员,我大概率会忽略 blame 这条反馈,因为除非 Wikipedia 编辑者里这个术语比我想象的更常见,否则它主要只会和软件工程师画像共鸣。我更倾向先优化“Comparing differences”这段看起来很晦涩的文案。再就是把 IP 地址/用户名字段明确标注为作者,这似乎是个直接且高价值的可用性改进,尤其在匿名编辑常见时。
- 这是我选的两个测试。你选的是否同样常见,或更常见? 我假设大多数人是从 View History 页面进入 WikiBlame,因此先测这条路径。先创建一个简单测试页并做几次编辑,再渲染对应 View History 页面。在页面中找到“Find addition/removal”,取出通向 WikiBlame 的链接。接着我希望确认最基本搜索可用,尤其考虑那些预填参数框:向 Search 框填一个词并模拟点击 Start。结果校验我会做得较轻,因为结果列表细节大概率已有功能测试更深入覆盖。 我还假设热门页面也是 WikiBlame 高频使用场景,所以要测可扩展性。先观察像 Taylor Swift 这类页面的编辑量,再程序化生成一个有类似长历史、且编辑分散在文档各处的测试页。随后在该页发起搜索查询,确认在超时阈值内完成。同时校验结果,确保返回该术语对应的正确编辑数量。
- “Make words appear one line at a time” 这句是为了帮助不知道“Animate”术语的人也能找到文档,它服务于发现(discovery)场景;“Animate”则服务于已经知道所需功能名的用户,帮助他们进入理解或使用场景。