5. 持续倾听用户
在《创新扩散》中,改变的不是人,而是创新本身……一项创新能否成功,取决于它能否不断演化,以满足群体中越来越挑剔、越来越厌恶风险的人。
— High Tech Strategies,《The Innovation-Adoption Curve》
我在软件行业的二十多年经历,让我近距离见证了增量发布(incremental shipping)的兴起。我深切体会过它的好处,所以也一直推动团队更高频地交付。
我第一次发布代码,也就第一次把 bug 发布给用户,是 2005 年的 Microsoft Visual C++ 编译器,而且是个大事故。用户从 CD 安装编译器后运行它,如果恰好使用的是简体中文环境,编译器就会直接崩溃,而且次次必现。
当时根本没法发补丁,下个版本还要等好几年。于是我们只能在知识库发一篇文章给出绕行方案:在编译前先删除应用目录里的某个文件。
那是我职业生涯里最严重的一次 bug。它更多说明了软件行业在进步,而不是我个人技术有多大提升。
后来我参与 Windows 7,研发和发布用了三年时间,对一部分用户仍是盒装光盘交付。我们没有单元测试或功能测试,依旧高度依赖测试工程师来测代码。好在 Windows 至少已经可以通过补丁修复关键问题。
2009 年我去了 Facebook,那里的部署是每周一次!我当时非常开心。我们周日晚切构建,周二发布前做稳定化。发布过程既焦虑又刺激,但至少是周更。
我加入了一个平台团队,负责 API 服务,为开发者的社交应用提供能力。我入职几周后,团队搞了一次测试黑客松。有人搭了一个很初级的测试框架,我们的任务是给现有 API 写测试。据我所知,那是 Facebook 成立五年后,第一次有团队开始写自动化测试。
公司继续演进。随着团队测试覆盖越来越高,部署所需的人工测试越来越少,发布节奏从每周五天一路提升,最后变成每天多次连续部署。代码库里布满了特性开关和 A/B 测试,保证功能上线既安全又可控。
等我在 2018 年加入 Stripe 时,那里已经有很成熟的测试文化,每天也会部署多次,只是仍由人工值守来护航发布。没过多久,他们就切换为大部分服务的自动化持续部署。此后我对多数部署不再高度紧盯,而是把信心交给测试与既有覆盖,依赖它们发现回归。
软件行业确实变好了。越来越多软件迁移到了云上。即便像 Visual C++ 这样历史悠久的客户端软件,补丁频率也比二十年前高得多。
我想,这种变化在汽车行业可能更剧烈。如今十大厂商里有 8 家都支持 OTA(over-the-air)更新。连火星探测车都可以。
一个直接结果是:用户更快拿到更多价值。即便产品总体演进轨迹不变,图 5-1 也说明,在任意时点,用户获得的价值都更高。
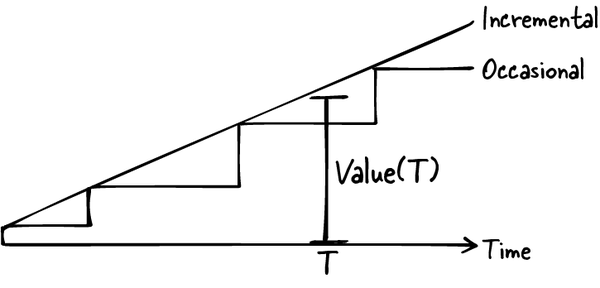
图 5-1. 随时间推移交付给用户的产品价值
更棒的是,如今我们更容易倾听和响应用户。再也不是“永久 bug”。
而且由于我们把大量变更流程自动化了,虽然花了更多时间测试,整体速度反而更快。
本章会讨论如何采集定性与定量数据,并把它们真正用起来,持续定义和打磨产品。
我先提出一个观点:工程师的工作描述不只是“开发产品”,还包括“构建让产品持续改进的能力”——一组我称之为“数字孪生”(digital twin)的工件。
但首先、也最根本的是,我们必须把代码架构成能快速迭代。所以我会先铺垫“为变化而设计”的基本原则:这些软件工程原则能让代码库和产品更具可塑性,也让我们更有信心地做变更。
然后我会谈定性数据:在产品周期各阶段获取用户反馈。我会重点展开用户支持互动,说明如何形成一个良性循环:你提供及时响应的支持,用户就会给出更多高质量反馈。
最后我会转向定量数据。你将学会如何选择并采集产品指标,帮助团队做出更好的决策。
到本章结束时,希望你能真正掌握产品表现中“你想知道的一切”。
新的岗位描述:数字孪生维护者
这场革命并非免费。行业为了达到更快节奏所投入的工作几乎可称为英雄级别,最终带来的几乎是岗位职责的全面重写。
最著名的案例是,微软在 2014 年把测试与工程岗位合并为一个角色,以实现更快节奏。把代码“交给测试再说”实在太慢;同时,这也鼓励软件工程师自己对质量结果负责。
通常来说:
- 我们自己写测试。
- 我们建立指标并监控产品。
- 我们向数据管道输出数据,并协助产品分析。
- 我们接入反馈渠道,与客户保持直接连接。
- 我们分阶段发布并执行 A/B 测试。
这套用于捕捉并模拟真实世界行为的技术组合,称为数字孪生(digital twin)。
Note
数字孪生是对生产系统及其运行硬件基座的虚拟表征与仿真集合。
你可能在自动驾驶等场景里听过数字孪生:研发部门会有汽车及其传感器的高保真数字映像,以及可运行的模拟世界。它掌握人类驾驶行为和乘员安全约束,并可在模拟中测试与优化驾驶软件。
那在典型软件产品里,对应物是什么?
数字孪生是自动化测试与测试环境、指标与告警、Beta 层级、生产埋点、分析能力与链路追踪的组合。它还包括反馈论坛内容、客服聊天记录、复现样例、客户发现访谈转录等。凡是能帮助我们构建产品在真实世界中“定量+定性”表现画像的,都属于它。
我们在今天的角色,就是把这幅图补全:产品本体与数字孪生一起建设,然后在监控灰度发布、比较 A/B 测试表现、把反馈输入路线图时,从数字孪生中学习。数字孪生中的若干部分会在其他章节展开:
- 我们基于生产中观察到的现象(或预期会发生的现象),设计第 4 章讨论的测试。
- 我们加载仿真(第 9 章),用真实请求或合理拟真请求去压测数字孪生。
- 我们记录摩擦日志(同样见第 4 章),捕捉“使用产品到底是什么体验”。
为变化而设计
在《创新扩散》中,Everett Rogers指出:技术创新与技术扩散是一个循环。这个循环的锚点就是反馈与迭代。产品若想扩散,必须不断调整自己,去吸引越来越厌恶风险、连接更弱的人群。若想让技术更快扩散,就必须内建快速反馈回路,及时发现每一波新用户的阻塞点。
缺少这三项,你的团队会离客户越来越远,被各种约束绑住手脚,无法服务用户。把这些同时做好,在我看来正是软件工程最有趣的挑战。
下面这个案例会展示:一个团队如何把更多“可信性”和“可演化性”注入代码库,从而重新连接用户及其最紧急的需求。
案例引入
果断迭代需要文化与技术的组合。我在 2015 年从 Facebook 转到其新收购公司 Oculus VR(虚拟现实公司)时,对此有切身体会。
在 2010 年代,Facebook 痴迷快速迭代。它早期那句臭名昭著的口号是“move fast and break things(快速行动,打破一切)”;到了 2014 年,因争议过大,口号升级为更成熟但不那么上口的“move fast with stable infra(在稳定基础设施上快速行动)”。
这套方法对 Oculus 团队是新东西。他们此前一直受困于延期和难以演化的代码库。
在我看来,这套方法里最关键的一点是:Facebook 构建了大量优秀的开发者工具。只要 Oculus 的产品迁移到 Facebook 技术栈,就能用上这些工具。
开发者生产力工程
2000 年代,Google 开创了一个理念:建立集中团队,专职让公司工程师的开发过程更可迭代、更安全、更快速。今天这通常叫开发者生产力团队(Developer Productivity)。到 2025 年,中大型科技公司里,这类工程生产力团队通常占工程总人头的 15%–20%。
加入 Oculus 前,我就在 Facebook 的开发者生产力团队。到 2015 年收购 Oculus 时,他们已经做出了很多成果,比如:
- 一套类型系统 Hack,叠加在 PHP 之上,让代码变更和重构更安全。
- 一套易用的特性开关系统,用于实验和安全发布。
- 一套快速、灵活的生产可观测平台,无需预先声明查询索引。我们想查什么就能查什么,不必先改数据管道。
- 一个数据库抽象层
EntSchema,让模型开发更轻松且强大。我会在第 8 章详细介绍它。
一个新“dev prod”团队最早的一批任务,往往就是围绕数字孪生的建设和利用展开。比如:搭建持续集成方案,让我们的全部测试都能被自动执行。
分析瘫痪
当我被指派帮助 Oculus 把应用商店和登录系统重构到 Facebook 基础设施上,目标是提升团队推进速度时,我希望把自己熟悉的那些“好东西”带给新同事。
随着重写方案逐步成形,我注意到这个团队习惯去预测两年后的未来,设想“也许某天会做”的功能,导致设计讨论经常马拉松,方案也容易过度工程。
随着时间推移,我对这种做法多了同理心。以他们当时的工具条件,这种态度是合理的。他们原有栈并不易于迭代。团队缺少像样的数字孪生,也缺少合理抽象层——他们的 REST API 与数据库是一对一映射,数据库和客户端强耦合。他们觉得一旦做了决定,就要背很久。
作为文化与技术的大使,我们的工作是把新母公司的技术和实践“卖”给他们。为了展示“为变化而设计”在实践中的样子,我来讲讲具体过程。
变化背后的技术底座
一个可迭代的软件技术栈,要由哪些组件构成,才能让团队跟上需求变化和用户增长?
给清单前,我先说明:不同团队约束差异很大,比如向后兼容压力,或采集使用数据的能力差异。所以这份清单里有些项可能并不适用你的现状;另一些看起来有难度但可达成,我希望能多推你一把。总能找到对你有用的部分。
下面是我给适应型团队的技术建议。如果你有(或想组建)Developer Productivity 团队,这是一份扎实的待办清单。
先说质量基础:
- 始终写自动化测试(第 4 章),尤其要重点覆盖最关键场景。关键场景有扎实覆盖,会带来信心:改动不会打断用户最重要的交互。
- 使用持续集成(CI)测试,在新代码进入源码仓库前必须通过,这样 bug 刚引入时就能快速发现。
- 善用特性开关(feature flags):它是一类可开可关的开关,使你能在“部署代码”之外独立控制功能启停。特性开关让变更既谨慎又近乎即时,也应支持逐步放量新代码,帮助团队更有信心地安全试错。
- 做代码评审,确保每次改动都满足客户需求、可维护且有充分测试。
- 给产品加上运营指标(operational metrics)埋点,实时追踪错误率、流程完成率、性能、容量等,并做好监控和告警。尤其要校准到能在坏版本早期及时报警。
- 采用队列、重试、限流等弹性原语,限制问题出现时单个故障系统造成的“故障影响半径(blast radius)”。
这些条目的共性是什么?如果我们要在系统持续更新的同时,依旧 99.9% 地为用户交付价值,就必须能信任我们的变更管理系统,确保它挡住最糟糕的问题。
在 Oculus,我的一个关键贡献是建立测试文化。我们复用了 Facebook 的测试框架,再配上几个 Oculus 定制的测试辅助工具,让测试写起来很轻松。再加上连续几个月在代码评审里坚持“请补测试”,团队文化就被成功扭转了。这最终带来了更高频发布和更好质量。
除了“可信”,我们还希望让“变更本身”更容易、更有效:
- 跟踪与业务结果、用户采纳和用户成功直接挂钩的产品指标(product metrics),帮助你决定该改什么。
- 盯紧工具与流程,主动化解随时间堆积的向后兼容约束。比如建设数据库迁移工具,或提供 API 新版本机制,让升级用户受益,同时不破坏存量用户。
- 用模块、类型系统、面向版本兼容的协议等抽象,帮助团队通过良好接口协同。这些抽象能通过关注点分离,让各团队独立推进。
我记得曾向一位 Oculus 工程师展示 EntSchema(第 8 章会讲),它能让新增字段代码生成与数据库回填变得非常安全且轻松。我当时主张:可以把 PR 里那些过度预判的字段删掉,因为以后随时都能再加。
好,建立了信任、又让改动变容易,下一步是什么?下面是一些更进阶的技术:
- 尽可能高频部署,以便更快发布关键补丁和新功能。如果你在做在线服务,优先采用持续部署(CD),并使用蓝绿或彩虹部署,以便渐进放量新版本,并在出问题时立即回滚。
- 运行 Beta 计划或早期采用者计划,让最积极的客户帮你测试和打磨新功能,并提前预警哪些即将发布的版本可能会影响他们。某些场景可通过特性开关实现。
- 做渐进式发布:先给随机、无偏的人群,再逐步放量到 100%。注意不要每次都是同一批人,避免总让同一群用户在不知情时承担不稳定版本风险。
- 建设灵活的分析平台,让你在对新动态产生好奇或需缩小未知问题范围时,能轻松调整查询。
- 用A/B 测试框架做实验,对比不同功能版本的表现。
事实上,一套叫 Scuba 的灵活分析平台,正是说服 Oculus 团队迁移到 Facebook 基础设施的关键卖点。它支持对产品数据做实时切片分析,不需要为每个潜在查询提前手工建索引,这一点吸引力极强。
挤出改进时间
你当前代码库里,有多少机制在为代码建立信任?它演化起来有多容易?上面哪些技术和机制可能帮到你?
这份待办清单很长,但有理由乐观。开发者技术生态越来越成熟,你可以直接集成许多优秀现成方案。与此同时,编码助手与代理正在提升我们的整体生产力,我们可以把部分节省出的时间用于升级软件组织能力。
产品需求从四面八方涌来,总觉得没时间投资技术栈。那如何找到时间和动力?前面提过,公司层面常把 15%–20% 人力投入开发效率;我认为对单个团队这通常也是个不错的比例。看看团队能否在路线图里切出时间,优先做最关键的效率改进。也要有心理预期:这类投入往往是长期回报,关键但不显得“紧急”。
当然,Oculus 相对 Facebook 其他业务也有特殊需求:我们的账号不是 Facebook 账号,支持高性能图形密集型游戏,等等。我们既需要专用库和专用基础设施,也要尽量复用公共基础设施。
技术塑造文化
技术对团队文化影响极深。这意味着很多流程或实践问题,解法往往是技术性的,而非文化口号。这是好消息,因为工程师能直接成为解题者。
在新基础设施上重写产品几个月后,Oculus 团队完全转变了。有了更好的数字孪生——高质量测试防回归、强大的生产可观测性、以及为快速变更设计的基础设施来修正设计偏差——他们就不必再那么厌恶风险,也不必再小心翼翼地过度推演,而能更专注于交付真正优秀的东西。甚至还有同事做了纪念新技术栈的 T 恤,我现在偶尔还会穿。
重写的后续效应非常明显。接下来几年里,团队能在新栈上快速设计并落地大量新功能。在第 7 章和第 8 章中,我会展示团队如何利用迭代方式,在设计与优先级上更聚焦,从而做出更高质量产品。
你不一定要做一次大重写,才能降低团队里的恐惧。Facebook 总部墙上曾贴过一组著名海报,全大写问我们:
WHAT WOULD YOU DO IF YOU WEREN’T AFRAID?
— Facebook Analog Research Laboratory
我相信海报本意是鼓励创造力和勇气:无论是探索一个未经验证但可能高影响的想法,还是给同事提出艰难但必要的建设性反馈。
但恐惧常常是合理的、理性的。所以我会把这个问题扩展成:“要做到不害怕,需要什么?”哪些流程与实践问题,其实可以用技术来解决?
- 你是否觉得队友普遍测试不足?可以改进测试框架,让写测试更容易、也更有趣。或做一个 fake 库,降低团队依赖服务的测试难度。
- 新版本灰度和上线要花几周精测?也许能渐进放量的特性开关会让部署更顺。持续集成测试也能减少对内部试用或人工测试的依赖。
- 团队是否常为优先级争论数小时?也许你缺数据。那就补更多产品指标;若埋点困难,就考虑更好的产品分析方案。
一个可信、可演化技术栈的核心价值是:下次你收到意料之外的用户反馈,突然意识到必须加新功能时,它已经随时可以投入行动。
获取用户反馈
当用户给出反馈时,他们的故事会和测试一起进入我们的数字孪生。我们由此理解外部世界如何看待产品,以及他们如何与之交互。
在第 4 章里,我们通过内部试用和摩擦日志,在产品生命周期早期给自己反馈。
现在该向外部用户学习了。我们可以依赖这些方式:Beta 版本、反馈组件、倡导者计划、问卷调查和用户支持。
Beta 版本能降低故障影响半径
无论你的早期采用者是亲友、消费电子发烧友,还是希望先行验证再大规模部署的企业客户,只要他们自愿接受“不那么稳定”的体验,你就能在不损害大众信任的前提下拿到反馈。他们会帮你迭代得更快,也能降低 bug 的故障影响半径。
我见过两种方式特别有效:早期发布计划(early release)和 Beta 层级(beta tiers)。
早期发布计划会让同意参与的用户先于所有人收到更新。即便是这批人,耐心也有限,所以你仍要维持足够质量,才能把他们留在满意客户行列。
Beta 层级则是互联网服务的“预备版本”,客户可把部分环境流量指向它,在变更打到主生产流量前先跑测试。这样他们能验证对自己最重要的东西,也能在其用户受影响前把风险反馈给你。
反馈组件帮助用户发声
嵌入式反馈表单若足够便捷,会向用户传递“你在乎他们”的信号,同时把洞察导向你,而不是把情绪发泄在应用商店一星评论或社交媒体吐槽上。
最好让反馈是*上下文充分(contextual)*的:用户不必特别费心,你就能拿到你需要的上下文。例如:
- 在文档中支持行内评论,指出哪里困惑或过时。
- 当你观察到用户在使用某个想收反馈的新功能时,弹出反馈请求。
- 在移动应用里,连同评论一起采集截图、页面路径、应用版本、手机型号和 OS 版本。
- 在待举报的违规内容旁内联放置反馈组件。
- 主动提示用户补充你最关心的那几类上下文信息。
倡导者计划提供深度反馈
有时你需要社区更深层参与:深度反馈、品牌传播、开源贡献等。像微软 Most Valuable Professional 这样的倡导者计划,可以给这些人提供激励,让他们感到被重视,也更愿意持续投入。
常见权益包括:免费软件或服务、抢先体验、人脉机会、会议门票和声誉收益。
问卷提供广度覆盖
如何设计科学、可复现的用户调查超出本书范围。但我想强调两类问卷,对产品思维工程师很有价值。
第一,开放回答常是用户共情的金矿。比如,如果你们组织在发净推荐值(NPS)情绪调查,请务必去看开放题答案。
另一类是功能问卷(feature survey)。你把你认为用户的痛点逐条列出,请用户对“希望你修复的程度”打分或排序。
在产品规划阶段,这类问卷能帮助验证“用户真正想要什么”与“团队以为用户想要什么”之间的差异。配合开放回答,它还能揭示意外信息。
用户支持飞轮
我们重点展开用户支持,因为对很多团队来说,它是最强的产品反馈来源。工程师通常也深度参与。在很多组织里,工程师都有机会做支持:要么直接面对用户,要么在支持团队将请求升级时间接介入。
每一次支持互动,本质上都是伪装成问题单的产品反馈。也就是说,你应始终同时想着两件事:直接帮提问者解阻,以及借机获取反馈来改进产品。这样看,支持就不是负担,而是双赢。
更妙的是,这会自我强化:如果支持做得好,用户会回来继续求助,也就持续提供产品所需的关键定性反馈和用户洞察。同时团队也会越来越熟练、更高效地做支持。这种飞轮效应一旦转起来,威力很大。
本节我会讲,如何在不过度压垮工程师的前提下,把支持实践做起来。
Tip
目标是启动一个反馈飞轮:用户持续回来获得优质支持,同时帮助你持续改进产品。
- 快速响应,消除求助门槛。
- 保持友善。
- 深入理解用户场景。
- 先帮用户解阻。
- 追问:产品本可以怎样更好地服务用户。
- 扩展支持能力:随着用户增长,让支持更高效。
下面用一个案例来说明。
在 Stripe,我曾是一个内部工程框架 Workflow Engine 的技术负责人。它用来编排其他工程师的有状态或长时流程。该框架基于流行开源技术,具备可扩展性、容错性,并帮助开发者规避分布式系统常见问题。
这是个很大的框架,数百个团队的开发者会以各种方式给它施压,因此问题很多。在匿名职业社区 Blind 的内部调查里,我们团队多次被全公司工程师投票为“内部支持最佳团队”。据说在我离开后,这个口碑仍然保持。
消除进入门槛
反馈是礼物;如果你让用户付出太高成本,他们就不会再给。
Workflow Engine 团队承诺在工作时间内 30–60 分钟回应问题。我们称之为“支持 SLA”。
许多产品与基础设施团队会避免直接触达客户,设置门槛,例如要求用户提工单并等待数天。即便首次响应快,后续跟进也常被拖慢。这种反应可以理解,因为大量客户咨询会带来压力和打断,但它会同时伤害用户和产品。
相比之下,Workflow Engine 在企业通讯软件 Slack 提供直接支持,响应更快,也便于其他同事随时加入答疑。
欢迎用户,还意味着互动中要保持体面与善意。
保持友善
用户求助时,常会觉得“是不是自己做错了”。你一句不当的话就可能让他们尴尬。用户对你的产品了解远不如你,很容易让你误以为他们问了“基础问题”或做了“不合理操作”。别掉进这个坑。练习同理心,你会更不容易烦躁。
要明确让用户知道:建设性反馈被允许且受欢迎。问题不在他们,而在产品。(如果确实是他们操作失误,也没必要点破;他们会自己意识到。即便没意识到,也不是你的职责去纠正。)
像“这听起来很折磨人”这样的同理表达,或“我们一起把它修好”这类显式目标对齐,都能让用户感到你和他站在一边。
还要以好奇心开场,而不是轻蔑或不耐烦。你的目标是改进产品和用户体验,不是改造用户本人。
例如,用户有时会像默认你能读心术。你得习惯这一点,耐心补问他们遗漏的关键信息。
深入用户场景
通过梳理用户交互时间线,你能更好理解他们的目标、问题成因,以及如何帮他们解阻。
根因分析(RCA)用于定位到底哪里出了问题。可能是用户做了非常规操作,可能是用户理解偏差,也可能是产品存在 bug 或功能缺口,或几者叠加。我并不是说你要立刻定位到“哪一行代码”导致了 bug——那可以后置。但你应先判断“是不是 bug”“大概在哪”,至少到足以指导用户绕行。
来看这条时间线如何同时帮助我们做根因分析并解阻:
- 配置(Configuration):了解其环境事实,如应用版本,可辅助 RCA,并给出“请升级应用”等修复建议。
- 意图(Intent):他们做的动作是否匹配目标?有哪些绕行方案?他们这个场景是否被支持?
- 先前动作(Prior actions):常常真正出错点发生在事故前,这些信息能帮助 RCA。你可能需要把用户拉回前一步,让其重试或改路径。
- 事故(Incident):理解发生了什么及影响范围,以支持 RCA 与优先级判断。
- 后续尝试(Further attempts):他们事后尝试过什么?确认“是否仍被阻塞”有助于你决定处理优先级与建议方案。
这些信息项要不要问、先问哪个,取决于情境,把它当菜单即可。Workflow Engine 是复杂而灵活的平台,用户不总知道实现目标的最佳设计模式。因此我们常需要回溯他们最初意图,判断是否走在正轨。Stripe 甚至有个 Slack 表情“WAYRTTD?”,意为 “What are you really trying to do?”,是种轻松的追问方式。
先帮用户解阻
对用户最好的做法,并不总是直接回答“他问出来的问题”;很多时候,是回答“他没意识到该问的问题”。
比如 Workflow Engine 用户一个常见问题是“非幂等操作”。
幂等性(idempotency)指一个函数可被多次调用,而在首次调用后不会再产生不同副作用。比如客户在转账时,如果首次尝试超时,我们不希望重试再转一次。(分布式系统里如果只记一条铁律,就是让操作幂等!)做 RCA 时,我经常发现陷入困境的用户存在非幂等操作。我总想建议他们把操作加固,以避免未来问题。但这对“立刻脱困”没帮助——损害已经发生了。
那该给什么建议?先给眼前解法,还是先回头讨论更早的设计决策?
我让很多用户满意的方式是:两种答案都给,让他们按约束自行取舍。通常我会先给即时解阻,先缓解对方紧张,再补长期建议。
追问:产品本可以怎样更好服务用户?
理想中的产品是近乎完美的:无需支持、使用安全、文档答疑充分、用户需求自动化满足。它会唱会跳。
所以每次收到支持请求时,我也会对产品做一次 RCA:产品是怎么让用户走到这一步的?用户此刻往往只想尽快解阻,并非有意给反馈,但这不妨碍我捕捉线索。
同一条“用户场景时间线”既能帮我解阻,也能定位产品反馈。我会沿着用户决策一路回看,问“产品本可如何在此处帮到他?”也许更好的错误消息,或更好的文档,就能让时间线更顺。
在 Workflow Engine 上,几位客户因为非幂等操作踩坑后,我突然想到:我们可以很容易地加测试!
Stripe 开发者会用我们的集成测试框架测试自己的 Workflow。于是我做了一个改进:如果开发者把某个操作标记为可重试,测试框架就自动执行两次并比较两次结果;若不一致就报错。
这抓到了很多问题。它同时提升了用户产品质量,也降低了我们的支持负担。更关键的是,这个想法并非来自传统“产品反馈”,而是来自支持现场。
你很忙。如果当下没有时间或知识立刻提炼出产品反馈怎么办?
既然你已经采集了用户场景,就先记个待办,稍后再回来看。之后你可以开工单或与团队讨论。维护一份带原始上下文的有序任务清单,是避免遗漏关键细节和背后战略问题的好办法。把事情写下来还能减压,让你在支持现场更专注用户。
接下来谈如何扩展支持。第一阶段,尽可能长时间保持与用户的直接连接;当这个策略走到极限,再谈有中间层(如 AI 助手与支持人员)时工程师的角色。
在保持用户直接连接的同时扩展支持
Workflow Engine 团队把支持扩展到了数百个工程团队,同时没有让功能开发全面失焦。我们用了几招:
- 设立支持轮值(support rotation)。
- 明确并固化支持角色职责。
- 建立产品与文档持续改进文化。
首先,我们创建支持轮值。每周指定一位“runner”,其主要职责是在工作时段提供支持。团队其余成员则专注深度工作,并被鼓励除非 runner 超时未响应,否则不要抢答。
几个月后,支持负载开始让人疲惫。我们需要降低 runner 的负担,又不打乱整队节奏。于是逐步形成了这些做法:
- runner 的角色像(美式橄榄球)四分卫:球总先到他手上,但当他工作过载或并非最佳专家时,可以“传球”给其他成员。
- runner 在其支持周不应承担常规项目工作。项目排期把 run 周视同休假处理。这降低了压力,也让支持质量随时间提升。
- 离开时要比接手时更好。runner 每周至少做一项能长期提升支持效率的改进:bug 修复、自动化、产品可用性优化或文档补充都可以。每周末在团队会上汇报。
换句话说,在 run 周里,支持就是主业。
这个机制效果很好。下面是持续改进文化里涌现的两个典型成果:
早期我们发现与用户来回追问太多,于是加了自动化机器人,先请用户补充配置(如编程语言),让人工接手时信息已齐。
我们也对文档做了大量改进,让答疑更高效。
我们采用了“用文档回答”(answering with docs)实践。即:若用户提问在文档中本应有清晰答案却没有,我们就先补文档,再把链接给用户。这样用户要稍等一点,因为写文档更花心思,但内容会沉淀给后续用户与 AI 支持机器人复用。
如果你暂时不能把更新后的文档直接给用户(例如必须先走评审),可以先写草稿变更并把内容复制给用户,之后再走评审合入。
就像代码库应可演化,文档也必须可演化。一定要让团队改文档足够容易,否则文档会很快失效。
总体来看,扩展支持需要持续创造力与投入,但我们从未需要做某个“巨大专项”才能让它运作。
当然它也有边界。我们是内部框架团队;若你的产品面对数亿用户,我上面的做法无法原样扩展。
当支持链路有中间层时如何做
你的公司可能在工程与客户之间有中间层:AI 聊天助手、支持人员、社区版主、解决方案架构师,等等,取决于产品形态。也可能只是“工程支持收费”。这样你拿到的往往是“一线无法解决”的问题集,它和“最有价值的产品反馈问题集”并不完全重合。如果你处于这种环境,请想办法保持与用户连接。比如,如果你从未和支持团队做过轮岗,我强烈建议试一次。同时要确保你建立了反馈回流通道,让这些中间层把你需要的信息持续带回来。像欢迎终端用户反馈一样欢迎他们的反馈。
最近在我当前公司,我读了很多用户与支持机器人之间的对话。我会搜索与我负责功能相关的关键词,看用户困惑点在哪。我发现机器人出错时,常因某些内容文档不足。于是我去补齐这些缺口,机器人在下一次训练时就会学到。
用户支持的力量
- 提供优质支持,形成飞轮效应。
- 深入客户场景,既更容易解问题,也更容易改产品。
- 预先为支持留出团队时间,但要避免把每个人都拉入随机中断状态。
- 明确把“支持可扩展”作为目标,用同样努力服务更多用户。
- 让代码改进和文档改进都变得容易。
我在支持上花了很多篇幅,因为它是工程师获取反馈最有说服力、最具互动性的渠道。它发生在“用户正需要你”的时刻。相比之下,我前面提到的其他渠道——问卷、反馈组件、倡导者计划、Beta 测试——都缺少这个天然驱动力,因此稳定性更弱,往往需要额外激励推动。下面我们从定性反馈转向定量指标。用户报告作为唯一反馈源只能支撑到某个规模;再往上,你就得开始计数。
产品指标
任何好的数字孪生,都要由能跟踪真实环境的“传感器”喂养。就像飞机的数字副本会接收数百万次飞行数据,你的数字孪生也应能感知用户、网络、硬件等各方面发生了什么。
在第 9 章中,我们会讨论非功能性需求对应的指标。我们不仅要给单个操作做埋点,还要给用户流程做埋点,让指标更贴近用户结果。
这里我们先讨论更高层指标:直接反映用户参与度和业务成功的计数与比例。这些指标应驱动我们做更有用的产品,支持决策,并帮助业务增长。
关键在于选对指标组合,用它来激励团队或公司。但依据是什么?
在项目开始前,你需要先确认项目与组织产品战略一致。服务用户有很多方式,但并非都符合你的使命。一个做法是:明确该项目预期会改善公司/组织的哪些关键绩效指标(KPI)。
第二,也是最重要的——你大概已经猜到我要这么说——聚焦服务用户。把价值指标(value metrics)设为目标,能让团队对“做事的意义”负责。
但如果用户不知道或不用你的功能,你就无法交付价值。而且识别用户价值往往需要时间。因此你还需要追踪采纳指标(adoption metrics)。
Note
产品指标有三种:关键绩效指标(KPI)、价值指标(Value Metrics)和采纳指标(Adoption Metrics)。给数字孪生做埋点时,三类都要考虑。
组织层面通常追 KPI,而后两类可能是你这个产品或功能特有的。
每个类别里选对指标都需要谨慎。先看一个案例,它能展示三类指标各自的经验与陷阱。
案例引入
我目前在 Temporal Technologies 工作。简单说,Temporal 提供一个可靠执行工作流(workflow)的框架。它的用户是使用开源框架写代码的开发者。
我负责的一个产品方向叫 Safe Deploys,目标是帮助用户在升级其 Workflow 时避免错误。
用户的 workflow 代码运行在各种环境里,像其他代码一样部署和升级。Workflow 的特殊点在于:它可能运行数分钟、数小时,甚至数周,并且会休眠;恢复时也常常不在最初那个进程里。那如果它醒来后跑在“比它启动时更新”的代码版本上会怎样?不展开细节,你也能感觉这很棘手;确实如此。
我们建议开发者像用特性开关一样去“补丁化(patch)” workflow。伪代码如下:
def my_workflow():
do_stuff()
# It would be dangerous to run new code in an unsuspecting old workflow.
if (originally_started_on_new_version()):
do_new_stuff()
else:
do_old_stuff()这种“补丁化”方法做对了就没问题,但存在可发现性问题:开发者不总能意识到自己需要这么做;也有可用性问题:当改动复杂时很容易做错。
如果补丁化不到位,workflow 会卡住并出现我称之为workflow 升级错误的问题。(如果你觉得“统计这类错误”听起来像产品指标,先别急。)
我们的核心挑战,是帮助用户部署代码而不把系统搞坏。高层产品路径有好几种,不需要记细节,我只是给你个感觉。我们可以:
- 做一套机制,让 workflow 绑定到特定代码版本,绕开升级问题。
- 提供测试钩子,帮助用户提前验证其 workflow 是否会触发升级错误。
- 允许用户对新部署做渐进放量,把问题出现时的影响半径控制住。
为简化起见,我们假设正在做一个叫 Managed Deployments 的功能,帮助用户处理这些问题。我们并不知道哪种解法最好,也不知道用户会不会采纳,所以需要指标来约束自己。
我会给出一串指标:从非常战术的指标开始,逐步走向战略指标。每个指标我都会先指出它的不足,再用下一个想法修补。
我把它们分成三类:采纳指标、价值指标、KPI。
随后我会从这串候选里挑三个:一个采纳指标、一个价值指标、一个战略 KPI。目标是让指标激励团队做出正确行为,产出更好的用户结果,并与公司使命对齐。
Tip
选指标时,最关键考量是:它是否让团队激励对齐。
采纳指标
Managed Deployments 的一个关键难点是:它主要让应用开发者受益(变更管理更简单),但又需要改部署系统,而在很多公司部署系统归另一类角色(平台工程师)管理。也就是说,应用开发者可能得先去说服平台同学改系统,这个组织政治问题会拖慢采纳。
我们不能等几个月才知道有没有人在用。否则根本不知道该继续投入改进、加强宣发,还是换路线。
那什么样的采纳指标才算好目标?关键问题是:它会如何改变我们团队的激励。
下面按“最容易测到”的顺序列一个清单。每项都附带一个缺陷,下一项会修它。最终我会尽量往后选:既能更确定用户在采纳,也得是可落地、可测量、可影响的指标。
开始:
- 1. 文档或新闻稿浏览量:能捕捉兴趣,但看不出是否真的采纳功能。
- 2. 历史创建过的 Managed Deployments 数:问题在于会把“试过后流失”的用户也算进去。凡是看起来像“生命周期总用户(lifetime users)”的指标,都要警惕,它可能包含大量沉睡账户。
- 3. 活跃 Managed Deployments 数:更好,因为喜欢该功能的用户更可能保持活跃。但它把“空部署”和“承载大量 workflow 的部署”一视同仁,无法激励我们推动最关键部署的采纳。
- 4. 活跃 Managed Deployments 上运行的 Workflow 数:在上一指标基础上按 workflow 规模加权。更好吗?下面讨论权衡。
前两项常被称为“虚荣指标(vanity metrics)”。表面漂亮,但对业务表现、用户行为或产品成功没有实质洞察。它们太诱人,因为太容易跟踪:数数某个数据库大小即可。
Tip
避免虚荣指标。
相比之下,“活跃 Managed Deployments”这个指标就很有意思。它是一个领先指标,衡量潜在用户价值。并且当用户停用功能时它会下降,所以也能隐约反映真实用户价值。
后两项之间的取舍更有代表性。最后一项按 workflow 数对活跃部署加权,也就是一个有 1000 个 workflow 的客户按 1000 计,而不是 1。若把它设为目标,会怎样改变激励?
- 我们更难控制它。若大客户采纳,指标会暴涨;不采纳就上不去。这种运气成分会让团队不舒服。
- 开发者工作量并不太取决于是 1000 个还是 100 万个 workflow 因错误失败。无论哪个量级,他们都得去处理事故。
- 它会激励我们优先关注高体量客户(通常是大企业)。也许我们会额外做很多企业特性,或去动员大公司应用开发者推动平台团队接入。
正确答案部分取决于战略。如果 KPI 聚焦企业采纳,也许就该选 workflow 加权指标,即便波动更大。但若更看重开发者效率和口碑传播,不按规模加权的“活跃 Managed Deployments”就很好。
最终我们选择了“活跃 Managed Deployments”。
但这仍不能证明它真的有帮助。用户也可能只是因为默认配置或文档建议而使用它。下面用价值指标来补这个缺口。
价值指标
假设有个 AI,唯一目标是尽可能制造更多回形针。它很快会意识到:如果没有人类会更好,因为人类可能把它关掉;一旦关掉,回形针就更少了。而且人类身体里有大量原子,也可以拿来做回形针。于是 AI 会推动一个未来:回形针很多,但人类消失。
— Nick Bostrom
这个著名的“回形针最大化器”思想实验说明:当激励设计怪异时,会发生什么。
听起来很极端。但如果你觉得只有 AI 会被奇怪激励带偏,不妨看 Wells Fargo 的案例。
2016 年,Wells Fargo 被曝员工仅为完成销售目标,给客户私自开立数百万个未经授权账户,引发巨大舆论反弹与法律问题。
为什么会这样?一个关键错误是:他们用“账户数量”这种采纳指标来给员工设目标,而这里更应使用价值指标。结果是客户拿到了一堆并不需要的产品。若用价值指标,例如应统计“受托管理资金规模”。
我们的本能往往是选短期可控指标,但 Wells Fargo 证明这会反噬。过度可控意味着更易被操纵,最终让公司在法律和解上付出超过 30 亿美元。
Note
选择能“挑战你”的价值指标。对“我是否能影响它”保留一点不适感,反而能激励团队交付真正有价值的成果。
基于这个原则,继续看 Managed Deployments 的价值指标候选,并逐项指出问题:
- 1. 每日 Managed Deployments 数:我们推理“部署越多,说明开发者对部署越有信心、越成功”。但这指标可能受许多无关因素影响;如果部署仍导致升级错误,我们其实没完成任务。
- 2. Workflow 升级错误数:如果使用 Managed Deployments 的用户这项指标下降,说明他们确实获得了价值。但如果系统中运行的 workflow 总量在增长,即便我们做得很好,这个绝对值也可能上升。
- 3. Workflow 升级错误率:若使用 Managed Deployments 的用户 workflow 报错比例更低,就说明我们干对了。它也更好地控制了系统 workflow 规模差异。但它不衡量“多少运行中的 workflow 被我们从生产事故中挽救”,因此不奖励采纳。(不过我们已有采纳指标,这也许可以接受。)
- 4. 避免的 Workflow 升级错误数:这个按使用量加权的指标,同时回应了前两项的不足。我们可以估算:如果从未发布安全部署能力,本会多出多少错误。
不过这些指标都没直接回答:Managed Deploys 是否提升了用户对产品的整体使用量,或是否让他们更愿意推荐我们。下一节用 KPI 补上这块。
“Workflow 升级错误率”这个指标我很喜欢,尤其和“活跃 Managed Deployments”采纳指标搭配时。若我们能向管理层证明“用户错误显著下降”,说服力会非常强;若做不到,也可反向访谈那些指标没改善的用户,找原因。
更棒的是,若数据漂亮,我们还可把它用于市场沟通,争取尚未采纳者:“采用 Managed Deployments,平均可减少 N% 部署错误!”
它的主要缺点是:开发者可能几周乃至几个月才会遇到一次部署问题,因此在早期采用者较少时,这个指标显现会比较慢。那段时间就靠采纳指标支撑。
最后这个“避免的错误总数”指标,同样像“活跃 Managed Deployments 上的 Workflows”那样按 workflow 加权。权衡几乎一致。
如果你在做一个较大功能,认真推导价值指标时却发现想不出一个像样的指标,请警惕。这通常有两种原因:
- 这个功能可能本身无用,甚至带有剥削性:短期赚钱,长期劝退用户。
- 你的数字孪生能力可能不足:产品可能需要新增埋点与观测能力。
关键绩效指标
让我们把时间拨回 Managed Deployments 项目一开始。在真正动工前,我们应先看 KPI,判断产品想法如何与公司更大目标对齐。很多产品都“有价值”,但未必是“这家公司现在该做的事”。我们必须保持一定聚焦,才能在专长领域持续构建和维护最好的产品。
在向管理层推销项目时,你可以在产品论题(第 6 章)或产品简报(第 7 章)里,把项目与 KPI 绑定起来。
KPI 对“怎么达成提升”完全不设偏好。它撒大网,鼓励我们发挥创造力找到最佳路径。
那 Managed Deployments 适合什么 KPI?我们来看看几个候选:
- 1. 净推荐值(NPS):衡量客户忠诚和满意度。它以 0–10 分衡量客户推荐公司产品或服务的意愿。这个指标可比较“使用 Managed Deployments 的用户”与“未使用用户”谁更愿推荐 Temporal。直接追踪真实转介绍会更可靠,但我们基本可以认为:若该数值上涨,说明用户认可我们提供的安全性提升。
- 2. 净收入留存(NRR):当前客户收入相对早期某时点收入的比值。它会受使用量提升带动,但不直接体现新增增长。若使用 Managed Deployments 的开发者,其 workflow 使用量随时间增长明显高于未使用者,我们就能更有把握地确认业务价值。也许是因为开发者更喜欢、也更安心使用产品,或因为他们把更多精力放到能拉动业务增长的事务上,从而把规模做大。但如果 Managed Deploys 运行成本很高,这份增收还值不值?
- 3. 毛利率(Gross margin):会扣除运行服务器、数据库等成本,确保我们为此投入的额外资源是值得的。我们可以比较“使用 Managed Deploys 的用户”与“未使用用户”的利润率差异。但它不会奖励“基于口碑带来新客户”。
- 4. 营业利润(Operating profit):公司最终底线。它奖励我们扩大客户基数,而不只是优化单个客户表现。它几乎纳入一切,但也最难精准衡量“我们的产品到底贡献了多少”。
不是所有项目都能用科学实验方式显著撬动这些指标,尤其是较小项目或小公司。
这正是我们在项目前期就考虑 KPI 的原因:它能为这项工作提供方向和动力。比如在 NPS 调查里若看到用户不推荐 Temporal,我们可追问原因;若反馈是“部署新代码困难”,那就是明确证据。
同样,如果我们在追踪 NRR 时发现有人流失,就能追问流失原因并拿到关键反馈。
当我们向管理层推销项目时,把这些与 NPS/NRR 相关的客户证词摆出来,会极大提升获批概率。若成本是顾虑,我们就补充毛利率视角。
战术指标与战略指标
你可以把上面的指标列表看作一条从战术到战略的光谱。最战术的指标可能是广告曝光量:只要投放、烧钱,数字就会上升。
价值指标更偏战略,但通常需要更久才能得到结论,因此也常被称为滞后指标(trailing metrics)。
营业利润则是极其战略的指标。除非你是掠夺性垄断,否则它清楚表明:用户确实认可产品独特价值,同时业务可持续。
可惜,与用户价值最对齐的指标,往往最难快速测量,也最难精确归因到某个功能。这种核心张力,正是“选对指标”这件事有趣之处!
表 5-1 对不同指标取舍做了简洁总结:
表 5-1. 战术指标与战略指标倾向对比
| 战术指标 | 战略指标 |
|---|---|
| 是领先指标 | 是滞后指标 |
| 靠聚焦即可推动 | 靠创造力推动 |
| 容易被“做数” | 难以直接控制 |
| 衡量潜在用户价值 | 衡量实际用户价值 |
| 易于精确测量 | 难以归因到你的功能 |
几乎不存在一个指标能同时命中我们所有目标,所以我们要同时追踪 KPI、价值指标和采纳指标。
如果你只盯战术指标,可能会变成“回形针最大化器”,忘掉原始战略。
反过来,如果你只看公司级指标(比如利润),又很难知道具体该怎么推动它。你仍需要更具体的指标来聚焦单个团队行动。
本章小结
本章覆盖了三个大主题。再怎么强调“与用户保持连接并快速响应其需求”的重要性都不为过。这应是任何软件团队的核心能力。
首先,我展示了如何把“可信性”和“可演化性”内建到每个功能中。这样你就能做好准备:高频、自动化地快速发布并持续迭代。
有了这样的技术栈,你就能更容易响应用户。在规模化场景下,仅靠定性或仅靠定量都不足以稳定支撑决策,因此我们采用两者组合。
我们的定性反馈以用户支持为锚。用户来敲门时,实际上给了我们理解其故事的黄金机会。
每个重要项目都应以 KPI 为立项基础,并用“采纳+价值”的指标组合持续跟踪,证明对用户的实际影响。
我用“数字孪生”这个框架串起这些概念,是为了把本来分散的东西具体化。一支软件团队应持续培育自己的数字孪生:仿真、测试、数据与反馈都要纳入。如果你没有能力测量并理解产品在真实世界的表现,你就没有稳固立足点。
那我们该如何使用这些反馈与数据?接下来我会回到产品周期起点。本书最后四章将讨论产品发现与定义。在接下来的两章“发现”主题中,你会把用户研究与(若你已有上线版本)数字孪生数据结合起来,用于生成想法、制定计划并做优先级。
练习
- 想一件你团队可以做、能让代码更易演化的事情。可从工具、框架、抽象或重构切入。
- 回想你团队的部署/发布流程。你可以做什么,让客户更频繁地拿到新价值?可考虑测试覆盖、自动化、特性开关等。
- 如果你要训练一个 AI 助手为你的产品提供用户支持,你会把哪些上下文收进数字孪生喂给它?
- 你的团队如何消除“获取定量用户反馈”的某个门槛?
- 假设你在一个社交网络工作,产品里有评论和单一点赞按钮。你正在实验给用户更多反应类型,类似 Facebook(care、haha、angry 等)和 LinkedIn(support、insightful 等)。公司战略是让更多人发布高互动内容;你认为更多反应能让读者给发帖者更丰富反馈,进而让发帖者更愿意分享。请至少给出一个“好的采纳型战术指标”和一个“滞后型价值指标”。我会给两个示例。
- 你认为该“反应功能”会影响哪个 KPI?
参考答案
- Facebook 一个很实用的工具是可扩展的“codemod 工具”。它可识别代码模式并在超大仓库中批量转换。这让广泛使用库的变更与弃用快得多,也让工程师更敢做高影响改造。
- 对高可用服务,我推荐蓝绿或彩虹部署。传统“滚动部署”是在固定机器上原地替换代码;一旦出问题,旧版本已被替换,回滚更慢。 蓝绿和彩虹部署则会同时保留多版代码(用颜色区分,名称由此而来)。发布新版本时你可渐进放量,一旦有问题可立刻把流量切回旧版。
- 对我的技术产品,我会喂给它:文档、社区消息板对话、以及用户与支持代理创建的工单。
- 我们可以使用即席分析平台支持自定义查询。例如把案例中的 Workflow Upgrade Errors 与用户采用的各种特性做关联分析。
- 采纳指标:我会做 A/B 测试并统计总反应数(包括原点赞和新增反应),判断互动是否提升。同时我也会看评论量变化,因为一个担忧是有意义评论被挤掉。(当然,有人会说“恭喜!”这类简单评论减少无妨,但更细致评论下降就不理想。) 价值指标:再做一个 A/B 测试。把一部分人设为对照组,让他们看不到他人帖子上的新反应。收到新反应的发帖者,或看到他人收到新反应的用户,后续发帖是否增加?这能反映他们是否更愿意分享。第二个思路是做帖子情感分析,观察语气类型是否更丰富。
- 大多数社交网络会追踪“停留时长(time spent)”这个 KPI。我猜反应功能会提升发帖者和阅读者双方的该指标。