9. 产品架构
在软件领域,我们很少拥有真正有意义的需求。即便有,衡量成功的唯一标准也是:我们的方案是否解决了客户对其问题不断变化的理解。
— Jeff Atwood
功能性需求 是我们为产品可供性设定的一组目标,即让产品做到用户想做的事。第 8 章其实一直在讨论如何满足功能性需求,只是当时我们没有这么称呼它。
如果我们只想到这一层,就会得到软件版的“波将金村”——界面看起来很好,却并不能真正工作。所以当我们思考 非功能性需求(NFRs)时,就要考虑工程师需要为之设计的关键属性,包括成本、可扩展性、延迟、吞吐量、数据一致性、弹性和可用性。别忘了隐私与安全,尽管本章不展开。
NFRs 是实现目标的手段,而不是用户目标本身;有时它们代表的东西,用户只会在出问题时才注意到。
我喜欢这个主题,因为它是本书里最偏工程的内容之一,却依然能从产品思维中受益。围绕这些因素做系统架构设计,是用户中心思维与系统中心思维的纯粹融合;同时,这也是产品经理和其他角色最不容易直接参与设计的领域。
这种融合有时被称为产品架构:在用户与业务约束语境下的系统设计。我喜欢这个术语,因为它展示了把这件事做好所需的完整思维跨度。
我会先打一些基础,说明如何把“编辑式思维”带入你的产品架构。
然后我会回到惯用案例研究,为后续各节建立语境。
第一类 NFR 提供快速、可靠的用户体验,比如延迟、可用性与数据一致性。
第二类是可扩展性因素,如吞吐量与隔离,通常只有在很多用户同时使用系统时才会显现。
我省略了最后一类同样重要的数据治理需求,比如合规、安全与隐私,不过这些也同样能体现产品思维的力量。
最后,我会讲讲如何向客户沟通,让他们清楚哪些系统特性是可以依赖的。
产品架构的基础
产品架构与交互设计有关。这是因为内部抽象本身就是微型产品,第 8 章里关于用例、三次法则、迭代开发等多数经验,同样适用。
但产品架构有其独特难点,因为非功能性需求很棘手。它们数量很多,而且常常难以同时满足,这意味着我们通常没有足够的时间和预算把它们全部做好。更糟的是,即便时间无限,它们之间也经常互相掣肘——比如:更强的数据复制会增加延迟,安全门槛又可能削弱可用性。
因此,我们必须把编辑式思维带入产品架构:用户到底真正关心什么?
为此,我在考虑某项改进时,会用四个方法来避免最常见的错误优先级。下面我会逐一展开:
- 拉远视角,看整体。
- 避免“路灯效应”。
- 讲清楚对用户的影响。
- 用能够跨越“系统-产品鸿沟”的技术来验证影响。
这些小技巧能帮你避免过早优化:在我们还没有充分理由投入成本之前,就去改代码提升 NFR。它们往往浪费时间,甚至会伤害其他需求。
这类情况很常见,所以我会逐条讲。
拉远视角,看整体
假设你可以做一些缓存,把算法从 O(n) 降到 O(log n) 或 O(1)。这看起来很重要,但它需要工作量,也会让方案更复杂。
先拉远看语境。这个算法的运行时间,相比其他问题可能微不足道。当两个问题属于同一类型,但重要性相差一个数量级时,我们可以说其中一个问题“碾压”另一个。
如果你的函数总是通过一次网络往返被客户调用,那么把函数执行时间削掉几个微秒几乎无关紧要。进一步说,如果那次网络往返只是触发一单要一周才送达的包裹,那么优化这次网络往返本身也几乎不重要。
这些例子里,你很容易证明某个优化是过早的。我们把它一般化。
避免路灯效应
很多工程师受过系统问题导向训练,天然会往“解系统问题”上靠。他们容易在不必要的加固和过早优化里钻牛角尖。
这叫 路灯效应(图 9-1)。故事是:一个醉汉在路灯下找丢失的钥匙,尽管他并不是在那里丢的。别人问他为什么在这找,他说:“因为这儿有光。”
我们的“亮区”,就是我们作为软件工程师的训练背景,以及我们最熟悉的那一角代码。
别做那个醉汉。如果你在读现有代码时发现某个数据库访问没有防竞态,在决定修复优先级之前,先在脑中模拟它在真实场景里发生的概率。
想让自己跳出“光照区”,就要在你正在解决的问题和背后的“为什么”之间画一条线——也就是迫使你思考这些问题的用户场景。
一个能让自己保持诚实的实用做法,是把理由写成“对用户的影响”。

图 9-1. 路灯效应
传达提案对用户的影响
你会怎么把你的方案卖给用户?他们不会因为“O(log n) 算法”而买账,即便他们知道这是什么意思。但他们可能会因为“页面加载提速 25%”而买账。
以吞吐量为例。如果你对用户说“我们应该把系统扩到每秒处理一百万请求”,他们大概率会一头雾水。可如果你算出一个典型活跃客户平均每 5 秒发一次请求,那么用“用户语言”你会说:“我们的系统支持 500 万并发客户。”前一句很抽象,后一句则能促使我们做更好的决策。我们可以据此基于增长率预测用户规模,决定何时投资扩容。
这种分析并不总是便宜,我也不想鼓励你在获得产品语境成本很高时过度思考。用最佳实践直接改进 NFR,本来就完全合理。拿数据一致性来说:对一些低规模应用,为了“安全起见”用数据库事务保证强一致性很合理。它还可能让系统更易推理,从而提升团队效率。如果未来产品规模上来后,这个全强一致事务成了瓶颈,再去放宽一致性保证也不迟。
判断何时需要收集产品语境、何时应回退到标准实践,是产品架构师的一项关键能力。
一旦你确实想收集产品语境,怎么做?这通常很难。选择一套能帮助你在不同抽象层来回切换的工具链会很有帮助:从底层系统抽象到面向用户的抽象。把它们串起来,你就能理解系统架构如何影响用户。
使用能跨越系统-产品鸿沟的技术
系统-产品鸿沟,指的是围绕计算原语构建的低层抽象,与为了支撑用户动作而构建的高层组件之间的裂谷。它关乎系统组件的固有限制,以及为了让整个产品可调试、可可靠运行,我们需要做什么。
这道鸿沟主要以两种方式出现:
第一,可观测性。当系统-产品鸿沟很宽时,我们很难判断底层决策对用户的影响。这会加剧路灯效应,因为我们缺乏“看全局”的能力。
- 如果我负责一个有特定延迟的微服务,这个延迟到底会多大程度影响产品流程?它也许和其他服务并行执行、根本无关紧要;也可能正处于关键路径。可观测性工具可以告诉我。
- 如果我在做前端,网页组件的高内存占用对应用峰值内存占用贡献了多少?峰值正是用户最受影响的时候。内存分析器可以帮忙。
第二,可靠性。组件有其基本限制,我们把它们放进产品时必须考虑。比如网络故障永远存在。每次我面对系统问题,都要决定:是直接修底层组件,还是把它放进一个能补偿其限制的上层语境。例如:
- 如果我在构建智能体 AI,LLM 不稳定但很强大。我可以使用带重试机制的框架来抵消失败,并加护栏确保 LLM 不会做不该做的事。
- 如果我通过网页提供静态内容,我不能让每个用户都直接打到数据中心,否则它会被压垮。我需要用内容分发网络做缓存,把副本放到更靠近用户的地方。
意识到同一个问题可以在栈的多个层次修复,非常重要。有了合适技术,我们要么能让底层限制变得无关紧要;要么在它确实重要时,能理解其影响并知道该聚焦哪些点。
案例研究导入
Stripe以极高规模处理在线支付。资金流动场景对规模与可靠性的要求,让它非常适合用于思考产品架构。
我会对我在那里工作时使用过的对象模型做一些修改和简化。Customers 从 Merchants 处在线购买商品。Merchants 拥有一个 Balance,用来追踪其账户中的资金。资金会定期打款给 Merchants;该余额不应为负,例如在向 Customers 处理退款时。
图 9-2展示了一个简化数据图,其中连线上的叉号代表一对多关系中的“多”端。图中的方框表示一个相当标准的电商数据模式:Customers 向 Merchants 发起 Payments;Merchants 维护 Balances,用来存储收到的资金并在需要时退款。
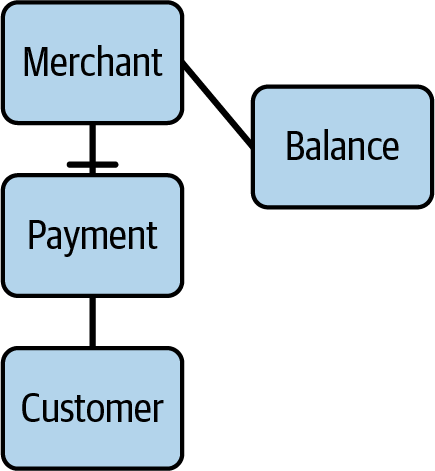
图 9-2. Stripe Payments 的简化数据模型图
这个设定提供了若干有趣的产品架构挑战;本章我们将带着它一起,审视几组设计权衡。
可靠的用户体验
让我们从“共情用户”的视角,来看一些最常见的可靠性与速度问题。这会帮助我们在产品架构上更有策略性。
请始终记住:延迟、可用性和数据一致性,实际上都只是代理指标。真正重要的是:用户是否会使用你的产品,并成功完成了任务?在这一节里,我会持续主张把思考拉回根本目标,并追踪“更贴近用户”的指标。
延迟
我会先讲一种自底向上、以系统为中心的延迟思考方式,然后再讲如何判断“延迟真正在哪些地方影响用户”。你会看到,这两者用到的技术非常不同;最后我会演示如何跨越把它们隔开的系统-产品鸿沟,以便从整体视角看完整问题。
衡量系统延迟最直接的方法,是给某个操作计时,例如端点(endpoint)、函数或远程过程调用。把结果塞进你喜欢的可观测系统指标里,你会获得很多好处:
- 给所有操作计时,你就有了完整的一组指标。
- 如果你已经识别出某次用户交互很慢,每个操作的细粒度数据能帮助你定位元凶。
- 优化某个操作延迟时,你可以直接从其指标里追踪改进。
- 当出现重大回退时,能及时告警团队。
这些数据很有价值。若延迟是关注点,你通常都应这样给产品加埋点。以 Stripe 为例,每个 API 调用都做了埋点,数据库和各个服务的延迟也被监控。但要注意,这些指标都像一盏路灯,诱使你过久停留在它的光里。归根到底,重要的是用户体验,某单一操作延迟上升,用户可能会感知到,也可能不会。
如何判断延迟问题到底发生在哪?先建立直觉,再谈更严格的方法。
以下是几个“试金石”与示例:
- 哪些操作是用户或上游系统在主动等待的,哪些是在后台发生的?用户希望立刻看到哪些内容(例如网页前几段文本),哪些可以稍后再来? 在 Stripe 这类公司处理支付时,常把请求拆成同步部分与异步部分:同步部分是校验资金是否存在、支付是否可成功;异步部分是写审计日志、把钱真正转到目标账户等。
- 哪些用户流程最常见?优先优化这些流程,能节省最多用户时间。 在 Stripe,优化支付流程延迟比优化 Merchant 注册更重要,因为前者的发生频率高了几个数量级。
- 用户在什么场景下对延迟最敏感?当用户尚未决定是否继续阅读/购买/浏览时,叫做低意图时段。用户在低意图时段的停顿中更容易分心。 例如,用户在浏览并把商品加入购物车时,延迟很容易让他们分心;而在完成购买时,他们通常更专注。 但如果用户信用卡被拒了呢?若你很久才告诉他,他可能已经切走页面,甚至不知道支付失败。我们应尽快完成所有校验。
这些直觉有帮助,但有时我们需要更严谨。把视角转到电商网站支付流程优化。通常客户会经历三个阶段:
- 逛商品并加入购物车。
- 打开结账页。
- 下单购买,然后进入支付处理。
假设我们要在这三个阶段中选一个优先优化。我们手头各有一些方案,能把每个阶段缩短几百毫秒,但实现成本都不低,我们希望先做影响最大的那个。甚至我们还不确定,延迟是不是最大问题之一。
我们真正关心什么?关键用户指标是转化率:从用户把商品加入购物车到最终支付,我们关心有多少比例的人能走完整个流程。我们的产品论题(见第 6 章)是:降低延迟会提升转化率。
转化率是场景指标的一个例子,因为它追踪的是用户在某个场景中推进后的结果。
我见过一种有效技术:做 A/B 测试。对三个阶段分别在小比例用户上注入人为延迟,比如增加 1 秒,然后与未加延迟的对照组比较转化率。优先去优化对转化率负面影响最大的那个阶段。
另一个场景指标是从加入购物车到进入结账的耗时。这个指标很值得追踪,因为我们能用很多方式改善它。比如在结账页加更好的 JavaScript 信用卡号校验(如 checksum),当用户输错时就能更快纠正并推进流程。我们可能不会给这类改动单独建一个指标,但端到端流程指标会捕捉到它。
如果这个指标在一次代码发布后突然飙升,怎么定位元凶?我们需要一种技术,把产品层指标和正在采集的细粒度系统指标连接起来。
分布式追踪就是这样的桥接技术。每条用户流程都带一个“trace ID”,贯穿所有相关操作。这些操作会带着该 ID 记录事件,我们就能按会话查询全部事件,找出大延迟发生在哪里。然后可以用火焰图或瀑布图可视化。
图 9-3是一个简化图,展示结账流程前两个阶段在不同技术层所花费的时间。
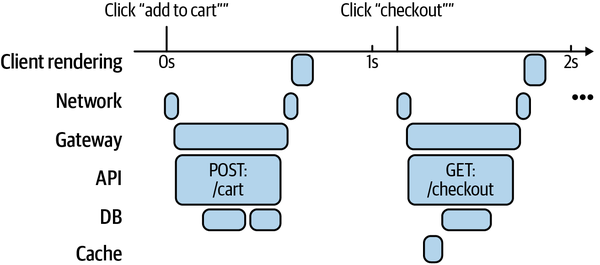
图 9-3. 电商结账流程延迟瀑布图
当不同抽象层能在同一张图里呈现时,我们最有力量。我们可以从整条 trace“放大”到某个问题点,也能在某个具体失败处“缩小”回它所在的全流程。像分布式追踪这类技术投资,很容易因为“不是天天用”而被推迟;但一旦用上,往往是 100 倍的生产力提升。
可用性
和延迟一样,你既要从用户视角优化操作可用性,也要理解底层系统行为。
看一个常见配置:网站有前端团队和后端团队共同维护服务。后端团队可能知道其服务端点请求成功率,甚至还监控流量,在异常下跌时告警。
但这些指标捕捉不到用户体验的很多部分:
- 网络请求是否真的到达服务端?
- 客户端重试是否在弥补服务短暂抖动,把可用性问题转化为延迟上升?
- 加载按钮的网页是否连按钮都渲染出来了?
- 用户是否在客户端就报错,导致根本无法调用服务端?
- 用户是否因 UI 近期改动而困惑,找不到按钮了?
这些团队协作起来,才能形成完整的产品体验画像。给客户端加监控会让你的洞察更贴近用户;再把这些指标和后端指标关联,就能更精准地定位可用性问题。
如果有能跨越系统-产品鸿沟的技术,客户端监控会更容易,例如真实用户监控(RUM)。这类工具可捕捉用户实际遇到的问题,包括页面加载时长、客户端错误、网络超时等,并把错误与浏览器版本、App 版本、地理位置等用户因素关联起来。
这里有一些能补偿系统可用性问题的技术思路:
- 工作流引擎:工作流可以跨多个阶段编排用户流程,同时给我们提供“全局视图”来看到底发生了什么。它对“完成整个流程”负责,通过重试单个阶段与管理并行性来提升对可用性问题的韧性。工作流也有助于可观测性。工作流通常对应某个产品功能或产品场景,并可追踪每一步。因此如果某一步失败或变慢,你既能知道对产品影响是什么,也能知道具体坏在哪。
- 内容分发网络(CDN):数据希望集中存储与管理在云服务里,但用户希望它离自己更近,以降低网络问题和延迟概率。CDN 在全球复制并缓存静态数据,字面意义上弥合了数据库与用户之间的距离。
数据一致性
从用户视角拆解数据一致性,是更难的问题之一。因为你可以提供不同级别的一致性,而它们之间常常存在尖锐权衡。正如 Martin Kleppmann 在优秀著作 Designing Data-Intensive Applications 中所说:“[一致性保证]不是免费的:保证越强的系统,可能性能更差,或故障容忍更弱。”
数据一致性保证有强一致、因果一致、最终一致等类型。这些术语有用但偏抽象。就本章而言,我聚焦于从“即时一致”到“最终一致”的光谱。(完全没有一致性保证的系统通常不直接面向用户。)
你还会看到像read-your-write 一致性这样的术语。就产品架构思考而言,我更喜欢它,因为术语里直接包含了用户——“your”。这一节我会按“谁受益”来整理不同一致性保证。我把产品里的参与者分成三组:你(当前用户)、其他用户、系统。
表 9-1展示了你可提供的不同即时一致性保证,从最常见到更强逐步增强。
表 9-1. 以用户为中心的一致性保证
| 保证 | 含义 |
|---|---|
| Write your Writes (WyW) | 所有后续写都基于你之前的写。 |
| Read your Writes (RyW) | 用户读数据时,能看到自己此前做过的全部写入。 |
| Write after system Writes (WsW) | 自动化与智能体触发的更新会立刻生效。 |
| Write after others’ Writes (WoW) | 使用产品的其他用户无法在不知晓你写入的前提下写入,反之亦然。 |
| Read others’ Writes (RoW) | 一旦其他人的写入成功被确认,你会立刻看到其结果。 |
| Read after system Writes (RsW) | 自动化与智能体做出的编辑一经系统确认就会立刻传播。 |
注意,这些保证是产品功能的属性,而不是数据库本身的属性。数据库通常并不知道“谁在读”,这意味着语义选择要由应用开发者谨慎完成。
事实上,你可以在弱保证数据库之上拼出更强保证;反过来,即使你对数据库发的是强一致查询,也不自动等于产品就有强一致。你会在产品架构多个层次上做决策。
例如,假设我们在为团餐下单场景构建端点(endpoints):不同用户可能同时编辑购物车,随后由订单创建者提交订单。下面按层看看如何为一致性做设计:
- Database:我们可以用事务型数据库让所有人的写保持一致,或者把问题放到更高层去解。
- System design:让每位点餐者在数据库里向列表追加,而不是在同一张表上做重叠写入。这会避免一整类 RoW 与 WoW 一致性问题。
- Endpoint inputs:我们不希望客户端重复发送相同请求导致购物车重复加单。可以让客户端提供幂等键(idempotency keys),在放行相同请求前检查该键是否已提交。
- Endpoint outputs:把更新后的数据返回给客户端。这样客户端无需再次查询并命中可能过期的数据库副本,也能看到购物车新状态。
- Clients:用 cookie 或本地存储保留数据,提高应用响应性,并定期刷新。
- Product decisions:当账户所有者进入结账流程时锁定购物车,避免“继续加单”和“提交支付”之间的竞态。若有人在最后时刻想加东西并抱怨被锁,所有者再手动解锁。
缩小“数据库能提供什么”与“产品真正需要什么”之间差距的桥接框架会很有帮助。比如,下面几类技术可用于“用户想要原子事务语义,但底层数据库不支持”的情况:
- 事件溯源(Event sourcing):这类框架本质上把发生过的一切记录成“事件”,并在故障时重放和续接。例如可基于检查点重建新数据库。效果上,一整条操作链会被组织成序列,用户感知到的是该序列整体的最终一致行为。
- Saga 模式:这种模式可叠加在事件溯源之上,在无法使用事务型数据库的操作之上,为产品功能提供“要么全部成功、要么全部回滚”的保证。你把一系列步骤串起来,并给每一步配一个失败时触发的“撤销”,系统确保最终要么全发生,要么全不发生。
- 数据完整性检查器:根据你关心的用户结果,检查多个数据库间的一致性,比如确保一笔金融交易后付款方与收款方记录匹配。
我们看到:把一致性当作用户中心问题来思考,并对产品设计做全局思考,两者结合就能创造更一致的体验。接下来谈这三类 NFR 之间的权衡。
延迟、可用性与数据一致性的权衡
Martin Fowler说过:“架构不是构建完美系统,而是做权衡。”所以我们回到 Stripe 案例,看看产品思维如何帮助我们穿越这些两难。
像 Stripe 这样的公司通常用分片数据库存储模型。每个分片会做多副本复制以防数据丢失。其中一个副本是接收写入的“leader”。从 leader 读可立即一致;但也可从其他副本读。这类读在数据传播完成前可能过期,通常称为从读(secondary reads)。
简而言之,主读取(primary reads)可用性更低但一致性更强;从读可用性更高但一致性更弱。
在 Stripe 早期,读取通常来自 leader,这让系统更易推理并保证正确性。但随着公司规模增长,它必须更规范化,让全公司工程师依据所服务的产品场景,在主读取和从读之间做选择。
练习一下:我们为几个 Stripe 场景选择语义,再选择实现方式。
- 商户入驻:申请人在表单中逐步填写资料以完成审核并成为 Merchant。流程应根据场景正确分支,比如个体经营者还是公司主体。最后还应允许其回看提交内容。这里需要 RyW 与 WyW 语义。最省事的实现方式是主读取(primary reads)。这个用例规模远不如支付高,因为一个入驻 Merchant 平均会关联数量级更多的支付请求,因此我们可以承受更昂贵的读写。
- 支付余额:当 Customer 向 Merchant 支付时,我们到底要在余额上强制什么?首先,Customer 余额不能为负,所以在其短时间连续支付不同订单时,这个对象应提供 WyW 语义。为实现该一致性,我们对 Customer 余额做主读取。相对地,收款 Merchant 不一定要立刻拿到钱——Customer 通常不关心对方何时到账,我们也不需要强制其余额上限。因此 Merchant 不需要 RoW 语义——当其查余额时,可做从读,看到的视图可能略旧。只有当他正和 Customer 当场对账时才会尴尬,而这显然很少见。
- 商户黑洞化(Blackholing Merchants):一旦发现某 Merchant 是诈骗者或恐怖分子,我们希望尽快关闭其收款能力。一个简单做法是在 Merchant 表写入一个“blackhole bit”,每次 Customer 尝试向其支付时检查该位。考虑到问题严重性,是否应给用户 RsW 语义,即每次支付都对 Merchant 表做主读取?这可能带来可用性和性能问题。但若使用从读,在高负载时安全更新可能传播很慢,虽然通常仍在几秒内。这要具体分析:如果把商户标为欺诈是人工审核流程的一部分,由 Stripe 分析师做判断并点击按钮,那么相对整个流程而言,多几秒传播通常无关紧要。但如果该动作是自动触发,用于对抗快速联动威胁,这点传播延迟就可能很关键。这个场景需要深入设计,也许应使用专门针对该类威胁优化的方案——比如采用不同数据架构,或提升自动触发安全修复的传播优先级。
不一致带来的后果可能严重伤害用户体验,但一致性本身也可能对可用性造成灾难性冲击。正如前面所说,Stripe 随时间从“处处强一致”演进到混合策略。
这次转变的关键节点之一,源于几年前的一次故障。
前文没提到的是,Stripe 还为 Shopify 这样的在线商店平台、DoorDash 这样的餐饮与配送平台提供服务。它们把 Stripe 支付与其他服务打包给自己的客户。为此,它们会批量(成千上万甚至上百万)入驻 Merchants,并为其接入 Stripe 支付。
故障源于一个细节:每当 Shopify 或 DoorDash 旗下 Merchant 从 Customer 收到一笔付款,就必须向平台支付一小笔费用。
我们在每次支付请求里都会把这笔费用同步写到平台的主库(leader)数据库。不巧,我们是同步执行的。这给调用方提供了 RyW 一致性——他们可以立即收到这笔费用的明细。平时没问题,直到某个承载我们最大平台之一的数据库分片宕机近一小时,结果挂在其下的每个 Merchant 的支付请求全部失败。
事故复盘后,我的紧急任务是把平台费写入改成异步,消除这个瓶颈,避免类似的大面积故障再次发生。随后团队对一致性策略做了更广泛评估,必然引出了对许多产品场景的分析。
对数据一致性的谨慎再审,是 Stripe 在近年稳定做到 99.999% 可靠性的关键部分。
可扩展性
在任何互联网产品里,规模一上来就会有问题。你的系统可能吞吐受限;一旦用户超过吞吐上限,后果可能很严重,成功的拒绝服务攻击就是例子。这源于缺少隔离:产品中的部分用户会负面影响其他用户体验。
限制吞吐的问题大致有两类:瓶颈与弹性。瓶颈是卡脖子点,阻止系统支持更多同时在线用户;而弹性问题指的是:系统“本可以”支撑更高吞吐,却对用户需求变化反应不够快——比如扩机器太慢。
这两类问题都可以通过测试提前定位,这也是本节重点。我们可以模拟用户争抢受争用资源、流量突变,以及故意超过吞吐上限,评估系统会退化到什么程度。
规模测试是个深而广的话题,本章不可能讲全。我会聚焦产品思维如何帮助你设计有效模拟,并让你更有信心去修复发现的问题。
规模模拟
整本书里,我们一直在模拟单个用户与产品/系统的交互。有时在脑中做,通过用户场景(第 1 章);有时在代码里做,通过场景测试(第 4 章);我们也让用户讲述自己的故事(第 5 章),并在客户发现访谈中模拟这些故事(第 6 章)。
但可扩展性动态太大,光靠脑补不够。我们需要更复杂的脚本来测试负载、流量尖峰和容量。
比起“test(测试)”和“injection(注入)”,我更偏好“simulation(模拟)”,因为你的主要目标之一,是构建尽可能贴近真实世界的测试环境与输入。对经验不足的工程师来说,“压测”听起来像“写个脚本对同一服务打几百万次请求就完事了”。
所以我使用以下术语,统称 规模模拟:
- 负载模拟(Load simulation):模拟一定量、真实生产风格的流量,判断系统能否扩到某个规模点。
- 容量模拟(Capacity simulation):类似测试,但会逐步增加这类流量,尝试找出系统极限,并观察触顶后的退化是否平滑。
- 尖峰模拟(Spike simulation):快速拉升流量,模拟真实请求突增,验证系统是否具备弹性。
Note
做规模模拟时,尽量追求高生产保真度。
先描述一个高保真规模模拟的理想图景,以 Stripe 这类互联网基础设施公司为例。设想你想知道:在当前系统下,负载翻倍是否可撑住;以及还能再扩多少容量。
- 在代码中加入指标、日志、采样和分布式追踪,以便排查发现的任何问题。
- 记录每个发起请求及其时间信息,方便重放模拟并复现问题。
- 复制一套完整生产集群,称为“影子集群(shadow cluster)”。它应尽可能接近生产,唯一差别是它不与外部世界交互。
- 每次请求进入生产集群时,复制成两条近似的合成请求(仅 ID 不同),一起发往影子集群。
- 在容量模拟中可提高复制倍数。
- 长时间运行,以捕捉“状态累积”导致的慢性问题,如内存泄漏、数据库索引增长等,它们会造成显著性能退化。
- 能继续拉高流量,以精确定位问题出现点。
- 监控场景指标,理解系统高负载时对典型用户的影响。
如果你要模拟的是新增一个大客户进入流量结构,也可以沿用同样架构,只是不做“流量加倍”,而是根据你对客户计划行为的判断,谨慎注入合成流量。这样能在既有总体使用背景下测试这位客户的流量。
这样的测试架构会带来这些收益:
- 能发现真实场景中会发生的问题,避免路灯效应。
- 工程师会更有信心地给问题排优先级并推进修复。
- 工程师可根据问题出现的规模点及流量增长预测,判断修复紧迫性。
- 团队可在同一套环境上验证性能优化效果。
这个愿景很全面,构建与运行成本也会很高。很多团队只能“因陋就简”。
下面我把它拆成一些可选的小建议。
规模模拟建议
在规模模拟中追求完整生产保真度是高目标。现实里,多数团队会在时间与预算允许范围内尽量接近它。
一种简单压测,比如高压请求某个已知可扩展性瓶颈端点(endpoint),因实现简单往往有不错投入产出比,尤其在你还没有真实用户流量可模拟之前。但它不能被误认为“全面测试”;若流量不真实,容易出现假阳性或假阴性。即便你走快速粗糙路线,也尽量喂给它接近生产的场景。
高保真模拟与简单定向压测脚本的组合也很有效:前者帮助发现瓶颈,后者让瓶颈更容易复现并验证。
首先,你通常会有一个发请求的测试 harness,以及一个接收请求的环境。这里要小心:
- 确保 harness 自身没有限制,导致无法模拟生产。例如用简单循环发请求可能有问题,因为每个请求会受上一个请求时序影响而排队。现实里,用户不会这样排队。
- 让模拟环境尽可能接近生产。甚至可以保留正常后台作业一起运行。
还要考虑如何激励队友真正去修复 harness 发现的问题:
- 关注可复现性。例如让 harness 确定性执行并使用随机种子,降低结果波动。
- 多花点时间让模拟“可信”。假设两种测试法:一种因为流量更真实,假阳性率 25%;另一种流量与现实关联很弱,假阳性率 90%。即便前者更难用,人们也会更愿意排查它报的问题。
- 用场景指标展示退化在现实中的影响。
如何模拟真实使用?影子跟随生产流量,或录制后重放,都是好实践。但如果你担心的流量与今天的实际流量不同,就需要预测客户真正会怎么用。
- 如果你服务的是少量大客户,与他们紧密协作一起做负载测试。
- 生成完整场景,而非单个调用。例如在 Stripe,客户可能先加载信用卡表单,随后很快提交支付。写一个把这两步串起来、并随机化间隔时间的场景。
最后,要注意时间维度:
- 现实不会停,所以要做长跑测试。你会发现状态累积问题,比如触发垃圾回收的内存泄漏等。
- 预测日历效应。例如:你预期流量是尖峰还是平滑?一天中的哪个时段会达峰,峰值是多少?一年中的哪些日子?在 Stripe,美国“黑五”和“网一”期间流量暴增,每年都要提前准备。
- 把性能画像记录到数据库里,这样产品演进时能持续发现回归。
桥接技术
市面上有很多负载模拟、流量捕获和故障注入工具,怎么选取决于很多因素。选择工具和方案时,把“能否建模生产”作为目标,同时确保你有足够埋点,在发现瓶颈后能快速调试。
向用户沟通非功能性需求
在线平台的客户不只想要可靠、可扩展的系统——他们还想要可兑现的保证。组织通常会和所依赖的公司协商,把某些质量门槛写进合同。作为工程师,你的工作常常是:搞清楚你能承诺哪些保证,向客户传递准确的信息,并做工程改进以达成可靠性目标。
围绕 NFR 与客户沟通有两个首要目标:对齐激励、建立信任。先说前者。
这些保证通常写在名为服务级别协议(SLA)的合同里,最常见约束包括:
我先讲最常见的 SLA:可用性。一个典型合同可能约定,在某时间窗口内,你的 API 调用至少 99.9% 必须成功。若公司达不到标准,就要对客户做补偿,比如以代金券形式退款。这类合同很重要,因为它会激励公司高度重视可靠性。
SLA 不是目标,而是下限。现实中客户往往希望更高可用性。平台公司通常会设定一个更高的服务级别目标(SLO)作为内部追求。这个目标通常不对外公开,因为可能让客户困惑或误解。
因此,公司还需要其他方式建立信任,证明自己不会只做 SLA 的最低要求。
- 在类似 https://status.stripe.com 的站点展示可用性,长期、真实地报告运行状态。
- 事故发生后向客户发布根因分析(RCA),更好的是公开到互联网。
- 事故处置期间持续同步进展,说明你做了哪些动作、速度如何。
- 列出你已完成或正在推进的整改,避免问题再次发生。
不要屈服于隐藏信息或找借口的诱惑,比如把责任推给你自己的基础设施供应商。这不会建立信任。
例如,如果你的云计算提供商是 AWS,你把某区域故障归咎于它,客户听到的是“你未来并不打算改进”。如果你改为说明将增加另一个区域或另一家云以应对灾难,客户会理解你在学习、在变好,也更愿意成为长期客户。
但在对客户透明之前,你必须先在内部透明。因为如果个人员工或其经理不敢讲出发生了什么——比如他们害怕被解雇或影响晋升——事实就会被掩盖,自然不可能传递给客户。这也是 Stripe 鼓励“激进透明”文化的一部分原因。
另一个文化实践,在 Facebook 与 Stripe 都极大加速了基础设施改进,那就是“无责复盘(blameless postmortem)”。在这种理念下,团队复盘生产事故时,主要聚焦导致事故发生的系统性失败,而不是责怪个人。当个人确有失误时,预期是学习改进而非惩罚。我很喜欢参加这种复盘——建设性、创造性,而且协作氛围好。
例如,如果某工程师在发布数据库时错误配置了一个参数,导致故障:
既然每一块基础设施本质上都是产品,那么无责复盘就是“责产品、不责用户”的实践。用这句话结束本章很合适。
本章小结
这一章把系统设计与用户中心思维综合到了产品架构领域。掌握产品架构能力后,你会做出更有策略、更有把握的选择,而用户也会因此受益。
我总结几个关键要点:
- 不要只在路灯下找答案。要依赖你对用户及其行为的理解。
- 拥有跨越系统-产品鸿沟的工具,你会轻松很多。选择工作流引擎、分布式追踪框架、负载模拟器等工具,既能从整体上建模产品行为,也能保留系统细节。
- 不要只看底层指标。要追踪并设定目标到那些直接关系用户的行为,如并发用户数、场景完成率、客户端可用性。
- 看待数据一致性,不要只盯数据库,要从用户视角理解“读到自己的写”“在他人写之后再写”等一致性概念。思考每个人的读写需要与谁同步,并创造性地在技术栈不同层次解决问题。
- 可靠性与可扩展性的思考中,权衡无处不在。理解用户真正想要什么,才能选对平衡点。
- 做规模模拟时,要尽量复现用户在真实世界里高强度使用你产品的方式。
- 如果你在做平台,务必通过诚实与透明建立客户信任,同时建立机制让双方激励一致。
下面是一些练习,之后我会结束本书。
练习
你正在给在线表格产品增加协同编辑功能,类似 Google Sheets。你希望支持最多 50 人同时编辑,以覆盖团队头脑风暴、黑客松任务认领等场景(人们会把自己的名字填进单元格认领任务)。要做到这一点,你需要同时思考可扩展性、数据一致性、竞态条件和可用性。
我建议你每看完一道题的答案,再进入下一题。
- 如果用户想稳妥、不丢数据,他们会希望你为每个单元格提供哪一类一致性保证?
- 针对上一题场景,如果你希望在数据库层提供这种一致性,可以怎么做?在产品层又该如何处理?
- Google Sheets 实际上并没有强制强一致性保证,可能是需求不足,也可能是他们无法在高代价下做出合适设计。它采用了简单的“最后写入者获胜”策略。不提供 WoW 语义的前提下,有哪些替代办法能尽量接近一致体验?至少给出两个想法。(我的答案里一个是 Google 已在做的,一个不是。)
- 你会收集哪些延迟指标或追踪数据,既能看清产品整体表现,也能在延迟回归时快速缩小问题范围?至少给出一个和上面编辑场景相关的指标,以及一个无关指标。
- 你会如何做“多人同时编辑文档”的负载测试,才能达到较高现实保真度?
答案
- 谨慎用户会希望有 Write after others’ Writes(WoW)一致性——他们不想在不知情的情况下把别人刚写入单元格的内容覆盖掉。
- Google 可以采用标准的条件写入方案。每个客户端为每个单元格维护一个序列号,表示自己本地副本的新鲜度。每次用户提交写入时,受影响单元格的全局序列号递增。所有写入都要求“序列号匹配”这个条件成立。因此如果你提交写入时发现全局序列号已经“领先”于客户端序列号,就不允许这次写入。 这种情况下该给用户看什么?可以弹窗展示最新值和用户自己的编辑,并给出冲突解决选项。 如果一次编辑影响多个单元格(如复制/粘贴)怎么办?我猜用户会希望原子性:要么全部应用,要么全部拒绝,然后展示冲突解决界面。否则跨单元格数据不一致会很快变得混乱且难管理。
- Google 会给每个用户分配一个颜色,协作者在某用户点击某个单元格时,会看到该颜色的边框。这个视觉信号非常强,提示“这里可能发生冲突”,让用户自行规避,而且实现成本对 Google 来说可能相对可控。这也提醒我们:谈数据一致性时,不全是数据库问题。解决方案越贴近用户,往往越有性价比,也越有针对性。 Google 也可以做我在上一题提到的序列号和历史追踪,但不是在检测到序列冲突后直接抛硬错误,而是在冲突单元格旁显示警告图标,让用户点击处理。为了支持这一点,Google 需要保留编辑历史,给用户提供足够上下文来有效解决冲突。
- 我会先测每次服务器调用耗时,这样能先把问题收敛到客户端或服务端,再进一步测服务端关键数据库调用。 我还会分别以及联合追踪“表格加载”和“表格渲染”,因为这是最常见场景之一,也直接决定用户第一印象。还会测从用户在单元格输入数据开始,到数据写入云端并传播给其他用户的总时长。 颜色边框这种一致性方案如果显示不够快就会失效,所以我还会测“用户点击单元格后,其他用户看到颜色边框”的延迟。
- 第一阶段,我会先定义一个接近上限的高规模真实场景,然后找一群用户在同一房间里高强度使用它。或者从真实使用里筛选一些高规模会话,覆盖我要验证的特征。不论哪种,我都会记录全部行为(当然先做数据匿名化),以便在“无头浏览器”中重放这些动作,做用户动作级的负载模拟。如果我只想聚焦服务端压测,也可以去掉浏览器,仅记录并重放服务端请求。 仅重放真实数据有个隐患:真实行为受很多因素影响。比如我优化了客户端渲染延迟后,用户操作速度本身可能变快,反过来给数据库更大压力。所以重大改动后我可能要重新模拟。 基于真实数据定位出问题后,我可以再聚焦系统局部,构建更定向的负载测试去打这些热点。这样优化反馈回路更短,最后再用原始模拟流量验证整体优化效果。
收尾
像海獭一样,产品思维工程师拥有一种稀有的能力组合。把场景、人物画像、意符、可供性等思维和你的技术能力结合起来,会形成一种“结构化共情”。这与工程学科天然契合,因为它能帮助你处理权衡。
要获得这些能力,最重要的事就是持续练习把注意力放在用户身上:
- 持续追问“为什么?”人们为什么这样行为?他们会如何从你构建的东西中受益?
- 验证你的软件。内部试用、测试、模拟,并让你和团队直接接触客户及其反馈。
- 迭代式构建,部分目的就是更频繁地接触用户。
- 练习模拟用户旅程。就像棋手能预看越来越多步,你也可以提升自己讲出更长、更好的用户故事的能力。
- 让你个人与团队目标和用户目标对齐,这会帮助你保持关注。
感谢阅读!希望这些内容对你有帮助。也欢迎反馈——如果你发现错误、认为我漏掉了重要权衡,或某些地方让你困惑,我仍然可以继续修改。
你可以在 LinkedIn 找到我,或在 Substack 关注 https://drewhoskins.substack.com,我在那里写软件工程与产品管理相关内容。